#BigQuery Data Engineering Agent
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
When “GIF” was named word of the year in 2012, Oxford Dictionaries U.S.A. credited Tumblr for pushing the word.
Text
BigQuery Data Engineering Agent Set Ups Your Data Pipelines

BigQuery has powered analytics and business insights for data teams for years. However, developing, maintaining, and debugging data pipelines that provide such insights takes time and expertise. Google Cloud's shared vision advances BigQuery data engineering agent use to speed up data engineering.
Not just useful tools, these agents are agentic solutions that work as informed partners in your data processes. They collaborate with your team, automate tough tasks, and continually learn and adapt so you can focus on data value.
Value of data engineering agents
The data landscape changes. Organisations produce more data from more sources and formats than before. Companies must move quicker and use data to compete.
This is problematic. Common data engineering methods include:
Manual coding: Writing and updating lengthy SQL queries when establishing and upgrading pipelines can be tedious and error-prone.
Schema struggles: Mapping data from various sources to the right format is difficult, especially as schemas change.
Hard troubleshooting: Sorting through logs and code to diagnose and fix pipeline issues takes time, delaying critical insights.
Pipeline construction and maintenance need specialised skills, which limits participation and generates bottlenecks.
The BigQuery data engineering agent addresses these difficulties to speed up data pipeline construction and management.
Introduce your AI-powered data engineers
Imagine having a team of expert data engineers to design, manage, and debug pipelines 24/7 so your data team can focus on higher-value projects. Data engineering agent is experimental.
The BigQuery data engineering agent will change the game:
Automated pipeline construction and alteration
Do data intake, convert, and validate need a new pipeline? Just say what you need in normal English, and the agent will handle it. For instance:
Create a pipeline to extract data from the ‘customer_orders’ bucket, standardise date formats, eliminate duplicate entries by order ID, and dump it into a BigQuery table named ‘clean_orders’.”
Using data engineering best practices and your particular environment and context, the agent creates the pipeline, generates SQL code, and writes basic unit tests. Intelligent, context-aware automation trumps basic automation.
Should an outdated pipeline be upgraded? Tell the representative what you want changed. It analysed the code, suggested improvements, and suggested consequences on downstream activities. You review and approve modifications while the agent performs the tough lifting.
Proactive optimisation and troubleshooting
Problems with pipeline? The agent monitors pipelines, detects data drift and schema issues, and offers fixes. Like having a dedicated specialist defend your data infrastructure 24/7.
Bulk draft pipelines
Data engineers can expand pipeline production or modification by using previously taught context and information. The command line and API for automation at scale allow companies to quickly expand pipelines for different departments or use cases and customise them. After receiving command line instructions, the agent below builds bulk pipelines using domain-specific agent instructions.
How it works: Hidden intelligence
The agents employ many basic concepts to manage the complexity most businesses face:
Hierarchical context: Agents employ several knowledge sources:
Standard SQL, data formats, etc. are understood by everybody.
Understanding vertical-specific industry conventions (e.g., healthcare or banking data formats)
Knowledge of your department or firm's business environment, data architecture, naming conventions, and security laws
Information about data pipeline source and target schemas, transformations, and dependencies
Continuous learning: Agents learn from user interactions and workflows rather than following orders. As agents work in your environment, their skills grow.
Collective, multi-agent environment
BigQuery data engineering agents work in a multi-agent environment to achieve complex goals by sharing tasks and cooperating:
Ingestion agents efficiently process data from several sources.
A transformation agent builds reliable, effective data pipelines.
Validation agents ensure data quality and consistency.
Troubleshooters aggressively find and repair issues.
Dataplex metadata powers a data quality agent that monitors data and alerts of abnormalities.
Google Cloud is focussing on intake, transformation, and debugging for now, but it plans to expand these early capabilities to other important data engineering tasks.
Workflow your way
Whether you prefer the BigQuery Studio UI, your chosen IDE for code authoring, or the command line for pipeline management, it wants to meet you there. The data engineering agent is now only available in BigQuery Studio's pipeline editor and API/CLI. It wants to make it available elsewhere.
Your data engineer and workers
Artificial Intelligent-powered bots are only beginning to change how data professionals interact with and value their data. The BigQuery data engineering agent allows data scientists, engineers, and analysts to do more, faster, and more reliably. These agents are intelligent coworkers that automate tedious tasks, optimise processes, and boost productivity. Google Cloud starts with shifting data from Bronze to Silver in a data lake and grows from there.
With Dataplex, BigQuery ML, and Vertex AI, the BigQuery data engineering agent can transform how organisations handle, analyse, and value their data. By empowering data workers of all skill levels, promoting collaboration, and automating challenging tasks, these agents are ushering in a new era of data-driven creativity.
Ready to start?
Google Cloud is only starting to build an intelligent, self-sufficient data platform. It regularly trains data engineering bots to be more effective and observant collaborators for all your data needs.
The BigQuery data engineering agent will soon be available. It looks forward to helping you maximise your data and integrating it into your data engineering processes.
#technology#technews#govindhtech#news#technologynews#Data engineering agent#multi-agent environment#data engineering team#BigQuery Data Engineering Agent#BigQuery#Data Pipelines
0 notes
Text
Soham Mazumdar, Co-Founder & CEO of WisdomAI – Interview Series
New Post has been published on https://thedigitalinsider.com/soham-mazumdar-co-founder-ceo-of-wisdomai-interview-series/
Soham Mazumdar, Co-Founder & CEO of WisdomAI – Interview Series

Soham Mazumdar is the Co-Founder and CEO of WisdomAI, a company at the forefront of AI-driven solutions. Prior to founding WisdomAI in 2023, he was Co-Founder and Chief Architect at Rubrik, where he played a key role in scaling the company over a 9-year period. Soham previously held engineering leadership roles at Facebook and Google, where he contributed to core search infrastructure and was recognized with the Google Founder’s Award. He also co-founded Tagtile, a mobile loyalty platform acquired by Facebook. With two decades of experience in software architecture and AI innovation, Soham is a seasoned entrepreneur and technologist based in the San Francisco Bay Area.
WisdomAI is an AI-native business intelligence platform that helps enterprises access real-time, accurate insights by integrating structured and unstructured data through its proprietary “Knowledge Fabric.” The platform powers specialized AI agents that curate data context, answer business questions in natural language, and proactively surface trends or risks—without generating hallucinated content. Unlike traditional BI tools, WisdomAI uses generative AI strictly for query generation, ensuring high accuracy and reliability. It integrates with existing data ecosystems and supports enterprise-grade security, with early adoption by major firms like Cisco and ConocoPhillips.
You co-founded Rubrik and helped scale it into a major enterprise success. What inspired you to leave in 2023 and build WisdomAI—and was there a particular moment that clarified this new direction?
The enterprise data inefficiency problem was staring me right in the face. During my time at Rubrik, I witnessed firsthand how Fortune 500 companies were drowning in data but starving for insights. Even with all the infrastructure we built, less than 20% of enterprise users actually had the right access and know-how to use data effectively in their daily work. It was a massive, systemic problem that no one was really solving.
I’m also a builder by nature – you can see it in my path from Google to Tagtile to Rubrik and now WisdomAI. I get energized by taking on fundamental challenges and building solutions from the ground up. After helping scale Rubrik to enterprise success, I felt that entrepreneurial pull again to tackle something equally ambitious.
Last but not least, the AI opportunity was impossible to ignore. By 2023, it became clear that AI could finally bridge that gap between data availability and data usability. The timing felt perfect to build something that could democratize data insights for every enterprise user, not just the technical few.
The moment of clarity came when I realized we could combine everything I’d learned about enterprise data infrastructure at Rubrik with the transformative potential of AI to solve this fundamental inefficiency problem.
WisdomAI introduces a “Knowledge Fabric” and a suite of AI agents. Can you break down how this system works together to move beyond traditional BI dashboards?
We’ve built an agentic data insights platform that works with data where it is – structured, unstructured, and even “dirty” data. Rather than asking analytics teams to run reports, business managers can directly ask questions and drill into details. Our platform can be trained on any data warehousing system by analyzing query logs.
We’re compatible with major cloud data services like Snowflake, Microsoft Fabric, Google’s BigQuery, Amazon’s Redshift, Databricks, and Postgres and also just document formats like excel, PDF, powerpoint etc.
Unlike conventional tools designed primarily for analysts, our conversational interface empowers business users to get answers directly, while our multi-agent architecture enables complex queries across diverse data systems.
You’ve emphasized that WisdomAI avoids hallucinations by separating GenAI from answer generation. Can you explain how your system uses GenAI differently—and why that matters for enterprise trust?
Our AI-Ready Context Model trains on the organization’s data to create a universal context understanding that answers questions with high semantic accuracy while maintaining data privacy and governance. Furthermore, we use generative AI to formulate well-scoped queries that allow us to extract data from the different systems, as opposed to feeding raw data into the LLMs. This is crucial for addressing hallucination and safety concerns with LLMs.
You coined the term “Agentic Data Insights Platform.” How is agentic intelligence different from traditional analytics tools or even standard LLM-based assistants?
Traditional BI stacks slow decision-making because every question has to fight its way through disconnected data silos and a relay team of specialists. When a chief revenue officer needs to know how to close the quarter, the answer typically passes through half a dozen hands—analysts wrangling CRM extracts, data engineers stitching files together, and dashboard builders refreshing reports—turning a simple query into a multi-day project.
Our platform breaks down those silos and puts the full depth of data one keystroke away, so the CRO can drill from headline metrics all the way to row-level detail in seconds.
No waiting in the analyst queue, no predefined dashboards that can’t keep up with new questions—just true self-service insights delivered at the speed the business moves.
How do you ensure WisdomAI adapts to the unique data vocabulary and structure of each enterprise? What role does human input play in refining the Knowledge Fabric?
Working with data where and how it is – that’s essentially the holy grail for enterprise business intelligence. Traditional systems aren’t built to handle unstructured data or “dirty” data with typos and errors. When information exists across varied sources – databases, documents, telemetry data – organizations struggle to integrate this information cohesively.
Without capabilities to handle these diverse data types, valuable context remains isolated in separate systems. Our platform can be trained on any data warehousing system by analyzing query logs, allowing it to adapt to each organization’s unique data vocabulary and structure.
You’ve described WisdomAI’s development process as ‘vibe coding’—building product experiences directly in code first, then iterating through real-world use. What advantages has this approach given you compared to traditional product design?
“Vibe coding” is a significant shift in how software is built where developers leverage the power of AI tools to generate code simply by describing the desired functionality in natural language. It’s like an intelligent assistant that does what you want the software to do, and it writes the code for you. This dramatically reduces the manual effort and time traditionally required for coding.
For years, the creation of digital products has largely followed a familiar script: meticulously plan the product and UX design, then execute the development, and iterate based on feedback. The logic was clear because investing in design upfront minimizes costly rework during the more expensive and time-consuming development phase. But what happens when the cost and time to execute that development drastically shrinks? This capability flips the traditional development sequence on its head. Suddenly, developers can start building functional software based on a high-level understanding of the requirements, even before detailed product and UX designs are finalized.
With the speed of AI code generation, the effort involved in creating exhaustive upfront designs can, in certain contexts, become relatively more time-consuming than getting a basic, functional version of the software up and running. The new paradigm in the world of vibe coding becomes: execute (code with AI), then adapt (design and refine).
This approach allows for incredibly early user validation of the core concepts. Imagine getting feedback on the actual functionality of a feature before investing heavily in detailed visual designs. This can lead to more user-centric designs, as the design process is directly informed by how users interact with a tangible product.
At WisdomAI, we actively embrace AI code generation. We’ve found that by embracing rapid initial development, we can quickly test core functionalities and gather invaluable user feedback early in the process, live on the product. This allows our design team to then focus on refining the user experience and visual design based on real-world usage, leading to more effective and user-loved products, faster.
From sales and marketing to manufacturing and customer success, WisdomAI targets a wide spectrum of business use cases. Which verticals have seen the fastest adoption—and what use cases have surprised you in their impact?
We’ve seen transformative results with multiple customers. For F500 oil and gas company, ConocoPhillips, drilling engineers and operators now use our platform to query complex well data directly in natural language. Before WisdomAI, these engineers needed technical help for even basic operational questions about well status or job performance. Now they can instantly access this information while simultaneously comparing against best practices in their drilling manuals—all through the same conversational interface. They evaluated numerous AI vendors in a six-month process, and our solution delivered a 50% accuracy improvement over the closest competitor.
At a hyper growth Cyber Security company Descope, WisdomAI is used as a virtual data analyst for Sales and Finance. We reduced report creation time from 2-3 days to just 2-3 hours—a 90% decrease. This transformed their weekly sales meetings from data-gathering exercises to strategy sessions focused on actionable insights. As their CRO notes, “Wisdom AI brings data to my fingertips. It really democratizes the data, bringing me the power to go answer questions and move on with my day, rather than define your question, wait for somebody to build that answer, and then get it in 5 days.” This ability to make data-driven decisions with unprecedented speed has been particularly crucial for a fast-growing company in the competitive identity management market.
A practical example: A chief revenue officer asks, “How am I going to close my quarter?” Our platform immediately offers a list of pending deals to focus on, along with information on what’s delaying each one – such as specific questions customers are waiting to have answered. This happens with five keystrokes instead of five specialists and days of delay.
Many companies today are overloaded with dashboards, reports, and siloed tools. What are the most common misconceptions enterprises have about business intelligence today?
Organizations sit on troves of information yet struggle to leverage this data for quick decision-making. The challenge isn’t just about having data, but working with it in its natural state – which often includes “dirty” data not cleaned of typos or errors. Companies invest heavily in infrastructure but face bottlenecks with rigid dashboards, poor data hygiene, and siloed information. Most enterprises need specialized teams to run reports, creating significant delays when business leaders need answers quickly. The interface where people consume data remains outdated despite advancements in cloud data engines and data science.
Do you view WisdomAI as augmenting or eventually replacing existing BI tools like Tableau or Looker? How do you fit into the broader enterprise data stack?
We’re compatible with major cloud data services like Snowflake, Microsoft Fabric, Google’s BigQuery, Amazon’s Redshift, Databricks, and Postgres and also just document formats like excel, PDF, powerpoint etc. Our approach transforms the interface where people consume data, which has remained outdated despite advancements in cloud data engines and data science.
Looking ahead, where do you see WisdomAI in five years—and how do you see the concept of “agentic intelligence” evolving across the enterprise landscape?
The future of analytics is moving from specialist-driven reports to self-service intelligence accessible to everyone. BI tools have been around for 20+ years, but adoption hasn’t even reached 20% of company employees. Meanwhile, in just twelve months, 60% of workplace users adopted ChatGPT, many using it for data analysis. This dramatic difference shows the potential for conversational interfaces to increase adoption.
We’re seeing a fundamental shift where all employees can directly interrogate data without technical skills. The future will combine the computational power of AI with natural human interaction, allowing insights to find users proactively rather than requiring them to hunt through dashboards.
Thank you for the great interview, readers who wish to learn more should visit WisdomAI.
#2023#adoption#agent#agents#ai#AI AGENTS#ai code generation#AI innovation#ai tools#Amazon#Analysis#Analytics#approach#architecture#assistants#bi#bi tools#bigquery#bridge#Building#Business#Business Intelligence#CEO#challenge#chatGPT#Cisco#Cloud#cloud data#code#code generation
0 notes
Text
Google’s BigQuery and Looker get agents to simplify analytics tasks
Google has added new agents to its BigQuery data warehouse and Looker business intelligence platform to help data practitioners automate and simplify analytics tasks. The data agents, announced at the company’s Google Cloud Next conference, include a data engineering and data science agent — both of which have been made generally available. The data engineering agent, which is embedded inside…
0 notes
Text
Key Technologies and Tools to Build AI Agents Effectively

The development of AI agents has revolutionized how businesses operate, offering automation, enhanced customer interactions, and data-driven insights. Building an effective AI agent requires a combination of the right technologies and tools. This blog delves into the key technologies and tools essential for creating intelligent and responsive AI agents that can drive business success.
1. Machine Learning Frameworks
Machine learning frameworks provide the foundational tools needed to develop, train, and deploy AI models.
TensorFlow: An open-source framework developed by Google, TensorFlow is widely used for building deep learning models. It offers flexibility and scalability, making it suitable for both research and production environments.
PyTorch: Developed by Facebook, PyTorch is known for its ease of use and dynamic computational graph, which makes it ideal for rapid prototyping and research.
Scikit-learn: A versatile library for machine learning in Python, Scikit-learn is perfect for developing traditional machine learning models, including classification, regression, and clustering.
2. Natural Language Processing (NLP) Tools
NLP tools are crucial for enabling AI agents to understand and interact using human language.
spaCy: An open-source library for advanced NLP in Python, spaCy offers robust support for tokenization, parsing, and named entity recognition, making it ideal for building conversational AI agents.
NLTK (Natural Language Toolkit): A comprehensive library for building NLP applications, NLTK provides tools for text processing, classification, and sentiment analysis.
Transformers by Hugging Face: This library offers state-of-the-art transformer models like BERT, GPT-4, and others, enabling powerful language understanding and generation capabilities for AI agents.
3. AI Development Platforms
AI development platforms streamline the process of building, training, and deploying AI agents by providing integrated tools and services.
Dialogflow: Developed by Google, Dialogflow is a versatile platform for building conversational agents and chatbots. It offers natural language understanding, multi-platform integration, and customizable responses.
Microsoft Bot Framework: This framework provides a comprehensive set of tools for building intelligent bots that can interact across various channels, including websites, messaging apps, and voice assistants.
Rasa: An open-source framework for building contextual AI assistants, Rasa offers flexibility and control over your AI agent’s conversational capabilities, making it suitable for customized and complex applications.
4. Cloud Computing Services
Cloud computing services provide the necessary infrastructure and scalability for developing and deploying AI agents.
AWS (Amazon Web Services): AWS offers a suite of AI and machine learning services, including SageMaker for model building and deployment, and Lex for building conversational interfaces.
Google Cloud Platform (GCP): GCP provides tools like AI Platform for machine learning, Dialogflow for conversational agents, and AutoML for automated model training.
Microsoft Azure: Azure’s AI services include Azure Machine Learning for model development, Azure Bot Service for building intelligent bots, and Cognitive Services for adding pre-built AI capabilities.
5. Data Management and Processing Tools
Effective data management and processing are essential for training accurate and reliable AI agents.
Pandas: A powerful data manipulation library in Python, Pandas is essential for cleaning, transforming, and analyzing data before feeding it into AI models.
Apache Spark: An open-source unified analytics engine, Spark is ideal for large-scale data processing and real-time analytics, enabling efficient handling of big data for AI training.
Data Lakes and Warehouses: Solutions like Amazon S3, Google BigQuery, and Snowflake provide scalable storage and efficient querying capabilities for managing vast amounts of data.
6. Development and Collaboration Tools
Collaboration and efficient development practices are crucial for successful AI agent projects.
GitHub: A platform for version control and collaboration, GitHub allows multiple developers to work together on AI projects, manage code repositories, and track changes.
Jupyter Notebooks: An interactive development environment, Jupyter Notebooks are widely used for exploratory data analysis, model prototyping, and sharing insights.
Docker: Containerization with Docker ensures that your AI agent’s environment is consistent across development, testing, and production, facilitating smoother deployments.
7. Testing and Deployment Tools
Ensuring the reliability and performance of AI agents is critical before deploying them to production.
CI/CD Pipelines: Continuous Integration and Continuous Deployment (CI/CD) tools like Jenkins, GitLab CI, and GitHub Actions automate the testing and deployment process, ensuring that updates are seamlessly integrated.
Monitoring Tools: Tools like Prometheus, Grafana, and AWS CloudWatch provide real-time monitoring and alerting, helping you maintain the performance and reliability of your AI agents post-deployment.
A/B Testing Platforms: Platforms like Optimizely and Google Optimize enable you to conduct A/B tests, allowing you to evaluate different versions of your AI agent and optimize its performance based on user interactions.
Best Practices for Building AI Agents
Start with Clear Objectives: Define the specific tasks and goals your AI agent should achieve to guide the development process.
Ensure Data Quality: Use high-quality, relevant data for training your AI models to enhance accuracy and reliability.
Prioritize User Experience: Design your AI agent with the end-user in mind, ensuring intuitive interactions and valuable responses.
Maintain Security and Privacy: Implement robust security measures to protect user data and comply with relevant regulations.
Iterate and Improve: Continuously monitor your AI agent’s performance and make iterative improvements based on feedback and data insights.
Conclusion
Building an effective AI agent involves a strategic blend of the right technologies, tools, and best practices. By leveraging machine learning frameworks, NLP tools, AI development platforms, cloud services, and robust data management systems, businesses can create intelligent and responsive AI agents that drive operational efficiency and enhance customer experiences. Embracing these technologies not only streamlines the development process but also ensures that your AI agents are scalable, reliable, and aligned with your business objectives.
Whether you’re looking to build a customer service chatbot, a virtual assistant, or an advanced data analysis tool, following a structured approach and utilizing the best available tools will set you on the path to success. Start building your AI agent today and unlock the transformative potential of artificial intelligence for your business.
0 notes
Text
Take Off İstanbul Day # 3: The Big Day for Startups
Take Off İstanbul Day 3 was very excited for startups. 50 startups selected with mentor votes made their presentation on Day 3. Startups in different verticals made their pitch deck to the jury of the leading Turkish and global mentors in different sectors. Besides that, presentations of Google and Invest in Turkey was pretty catchy for participants.
Why Invest In Turkey
Take Off İstanbul #DAY 3 started with Chief Project Director of Invest in Turkey Necmettin Kaymaz’s presentation. He talked about investing in Turkey and the support of the government for entrepreneurs. At the end of the presentation, Necmettin Kaymaz answered participants’ questions.
Google Training Session
Day 3 also included a Google training session in the afternoon. Trainer Devrim Ekmekçi was up first to talk about Measuring and Targeting for Startups, where he gave valuable recommendations on usage of Adwords & analytics, KPI Dashboards, and measurement of campaigns. Next up was trainer Yusuf Sarıgöz, who introduced Qwiklabs, Google’s online Cloud Training portal, before completing a hands-on session on Machine Learning.
Would you like to try Qwiklabs and receive Google Cloud training for free? Google has set up Cloud Study Jam-a-thon where you can learn more about Kubernetes, Machine Learning and BigQuery alongside many other Cloud concepts – enroll for free through this address (in Turkish) https://events.withgoogle.com/cloud-study-jam-a-thon/

Startup Pitches
In the afternoon, startup pitches are started. 49 semi-finalist startups made their pitch deck to the jury of the leading Turkish and global mentors in different sectors.
The semi-finalist startups that made a presentation are:
Auto Train Brain
Auto Train Brain improves the cognitive abilities of dyslexics at home reliably Website: www.autotrainbrain.com
Bren
Flexible Hybrid Nanogenerator running entirely industrial IoT device and wireless sensor without using a battery with battery-less sensor mode
Car4Future
Energy sharing network and transfer hardware developed with blockchain technology for electric vehicles and autonomous cars. Website: car4future.tech
Comparisonator
Comparisonator is a unique tool to compare players’ and teams’ performance data around the world. It assists scouts, sports directors, coaches, agents and players to make better and quicker decisions. Website: https://www.comparisonator.com
ConnectION
Connect-ION attracts attention to being an enterprise that starts out to transform about 1 billion cars in the world without autonomous vehicle technology to an autonomous car. It is aimed to make it available for non-autonomous vehicle owners to have an autonomous vehicle after an easy installation procedure without throwing their current car investments away. Website: www.connect-ion.tech
eMahkeme
“eMahkeme Online Incompatibility Solution Portal” aims to solve users’ judicial problems fast, safely and economically. Website: https://www.emahkeme.com.tr/
Fanaliz
Fanaliz helps companies measure credit risk in an easy, flexible and affordable way by applying algorithms based on data analytics. Website: https://www.fanaliz.com
FilameX
FilameX is a mini filament machine focused on the recycling of waste plastics and filaments to high-quality filaments. Website: https://www.3dfilamex.com/
HEXTECH GREEN
Develops and produces smart agriculture machines aim for indoor agriculture technology. Website: hextechgreen.com
Iltema
We are an R&D company that dealing with technical textiles and brings an innovative approach to heating needs in industrial areas, make them available for OEMs to reach the end-users. Website: www.iltema.com.tr
InMapper
inMapper is an interactive indoor map platform for large buildings such as airports,malls, offices. Website: https://inmapper.com/
Karbonol
Fuel from Cigarette Butt: Karbonol fulfills its production costs, and can solve the stub recycle problem. Website: www.karbonol.com
Meşk
Meşk Tech. is a İstanbul-based music technology company that provides unique software to revolutionize the eastern music education. Any person can learn and practice an instrument or develop vocal skills via using our Meşk App. Website: www.meskteknoloji.com
PACHA
PACHA; protein and collagen chips, %100 Natural and tasty functional food. Website: www.pachacips.com
PDAccess
PDAccess is a cloud security software that helps companies manage their clouds secure, agile and compliant. Website: https://www.pdaccess.com
Pirahas
A magical and revolutionary fully automated software at an unbelievable price for Amazon sellers. Website: www.pirahas.com
Respo Gadgets
Respo Gadgets is an Istanbul based medical device company that develops an innovative, silent, portable and comfortable oral device to be used in mild to moderate level obstructive sleep apnea and snoring treatment. Website: https://www.dormio.com.tr/
SafeTech
Safe Tech is an IDS and an IPS system that protects SCADA/Industrial IoT systems against cyber-attacks and operational threats. Website: www.smartscadasiem.com
Secpoint
To make and new perspective of cyber intelligence Website: https://www.secpoint.com.tr/
SFM Yazılım
SFM Software is a fast and accurate cost estimation software for the product to be manufactured by Small and Medium-sized Enterprises (SMEs) in the machine manufacturing industry and productivity software which increases the company’s productivity by up to 15% at no extra cost to the manufacturer. Website: www.sfmyazilim.com
T Fashion
T-Fashion is a platform that aims to provide customized live analytics and fashion trend insights to companies that operate in the textile industry via analyzing thousands of social media accounts by the use of sophisticated deep learning algorithms Website: https://tfashion.ai
Tetis Bio
TETIS BIOTECH is a biomaterial company producing high quality marine bioactive compound products for industries such as healthcare and cosmetics. Website: https://www.tetisbiotech.com/
Üretken Akademi
Training-oriented startup acceleration program that supports high school and university students to start-up. Website: uretkenakademi.com
User Vision
Uservision is a platform helping brands to acquire agile implicit, explicit and subconscious qualitative insights from their target audience leveraging AI. Website: www.user.vision
ARAIG Global
ARAIG Global is a new international company and partner of IF-Tech Canada. ARAIG Global is a licensed company for production and global sales of the product- Gaming vest. We have the exclusivity to produce, distribute and market the Gaming vest that gives gamers an experience unheard of. Website: araig.com
Augmental
Augmental is an educational technology application targeting middle to high school students where course materials are adapted to each student’s learning abilities using Artificial Intelligence and student engagement tools. Website: www.augmental.education
Beambot
BeamBot offers artificial intelligence software that utilizes the already existing CCTV feed for autonomous control of any facility in order to optimize operation expenses, safety and security. Website: www.beambot.co
BlueVisor
BlueVisor develops AI wealth management platform to lift financial burden so that people can enjoy a better life. BlueVisor mainly focuses on the B2B market with SaaS (Software as a Service) business model or platform. BlueVisor has made tractions already in a short period of company history. Website: bluevisor.kr&entrusta.ai
Cardilink
Displays the status of devices in a dashboard in real time and we analyze your data for the long-term monitoring and quality reports. Alarms and any occurring issues will be reported to you before the product will be used with a patient. Additional benefit for you: Data Analytics of your product for clinical studies. Website: www.cardi-link.com
DRD Biotech
DRD Biotech develops diagnostic blood tests for brain damage such as Stroke, Concussion, and Epilepsy. Website: www.drdbiotech.ru
Edubook
Edubook is an Interactive Learning Community that Provides a Safe Space for Educators and Learners to connect, collaborate, and communicate among each others. Website: WWW.EDUBOOK.ME
FIXAR AERO
FIXAR is an Autonomous commercial drone with unique aerodynamics. Website: WWW.FIXAR-AERO.RU
Hot-wifi
Guest wi-fi networks with marketing options & wi-fi analytics Website: hot-wifi.ru
Inspector Cloud
Inspector Cloud Website: http://www.inspector-cloud.com
InstaCare
InstaCare is transforming the typical healthcare infrastructure of Pakistan into a digital healthcare infrastructure in order to make it more accessible and reliable from the base of the pyramid to save lives over 2,000,000 people every year who die because of the current outdated infrastructure of the country. Website: https://instacare.pk/
Intixel
Intixel is building AI-based products to empower physician decisions as a second eye. Our Team is a finely selected Artificial Intelligence experts, engineers, computer scientists, and medical imaging experts. Website: www.intixel.com
Mazboot
Mazboot is the first Arabic in-app coach for helping diabetic patients self-manage their disease and get a consultation from doctors Website: https://www.mazbootapp.com/
MIFOOD
MiFood is a company that provides automation and robotization services for restaurants. Website: https://mifood.es
Monicont
Monicont is a next-generation utility, transforming lives and unlocking potential through access to energy. Website: https://monicont.com/
Otus Technologies
Otus Technologies develops a novel software tool for aircraft flight loads analysis and dynamic solutions. Website: https://otustech.com.pk
PakVitae
PakVitae provides lifetime affordable filters that can purify water to 99.9999% without any power requirement. Our technology revolutionizes the conventional water treatment processes. Website: https://www.pakvitae.org
Pharma Global
The system of technological solutions based on BigData and AI (e-commerce, e-learning, and marketplace platforms) that reduce costs for market access for pharmaceutical manufacturers. Website: https://pharma.global/
RAAV Techlabs
Data analytics and quality analysis instrumentation company, building devices to check the internal quality of agricultural produce and dairy, by non-invasive and non-destructive method, to give important information like nutritional and adulterants present in the produce. Website: www.raav.in
Torever
Torever allows travelers to plan their trips in a minute for free, and take back control of their journeys with accurate info and navigation on the go! Website: app.torever.com
UIQ Travel
Connects solo travelers with shared interests in-flight and in-destination. Website: https://uiqt.com
Usedesk
OmniAI-powered omnichannel helpdesk platform which supports customers and sales. Website: usedesk.com
UVL Robotics
UVL develops and produces of multi-rotary type UAVs with vertical take-off and landing on hydrogen-air fuel cells. The company was founded by leading experts in the field of aviation and robotics systems design with experience in scientific and industrial enterprises. Website: www.uvl.io
XYLEXA
XYLEXA is an early-stage company developing Artificial Intelligence(AI) based cloud the application which helps the radiologist in early, accurate and cost-effective diagnosis of breast cancer through mammograms. Website: WWW.XYLEXA.COM
1 note
·
View note
Text
Leverage Python and Google Cloud to extract meaningful SEO insights from server log data
For my first post on Search Engine Land, I’ll start by quoting Ian Lurie:
Log file analysis is a lost art. But it can save your SEO butt!
Wise words.
However, getting the data we need out of server log files is usually laborious:
Gigantic log files require robust data ingestion pipelines, a reliable cloud storage infrastructure, and a solid querying system
Meticulous data modeling is also needed in order to convert cryptic, raw logs data into legible bits, suitable for exploratory data analysis and visualization
In the first post of this two-part series, I will show you how to easily scale your analyses to larger datasets, and extract meaningful SEO insights from your server logs.
All of that with just a pinch of Python and a hint of Google Cloud!
Here’s our detailed plan of action:
#1 – I’ll start by giving you a bit of context:
What are log files and why they matter for SEO
How to get hold of them
Why Python alone doesn’t always cut it when it comes to server log analysis
#2 – We’ll then set things up:
Create a Google Cloud Platform account
Create a Google Cloud Storage bucket to store our log files
Use the Command-Line to convert our files to a compliant format for querying
Transfer our files to Google Cloud Storage, manually and programmatically
#3 – Lastly, we’ll get into the nitty-gritty of Pythoning – we will:
Query our log files with Bigquery, inside Colab!
Build a data model that makes our raw logs more legible
Create categorical columns that will enhance our analyses further down the line
Filter and export our results to .csv
In part two of this series (available later this year), we’ll discuss more advanced data modeling techniques in Python to assess:
Bot crawl volume
Crawl budget waste
Duplicate URL crawling
I’ll also show you how to aggregate and join log data to Search Console data, and create interactive visualizations with Plotly Dash!
Excited? Let’s get cracking!
System requirements
We will use Google Colab in this article. No specific requirements or backward compatibility issues here, as Google Colab sits in the cloud.
Downloadable files
The Colab notebook can be accessed here
The log files can be downloaded on Github – 4 sample files of 20 MB each, spanning 4 days (1 day per file)
Be assured that the notebook has been tested with several million rows at lightning speed and without any hurdles!
Preamble: What are log files?
While I don’t want to babble too much about what log files are, why they can be invaluable for SEO, etc. (heck, there are many great articles on the topic already!), here’s a bit of context.
A server log file records every request made to your web server for content.
Every. Single. One.
In their rawest forms, logs are indecipherable, e.g. here are a few raw lines from an Apache webserver:

Daunting, isn’t it?
Raw logs must be “cleansed” in order to be analyzed; that’s where data modeling kicks in. But more on that later.
Whereas the structure of a log file mainly depends on the server (Apache, Nginx, IIS etc…), it has evergreen attributes:
Server IP
Date/Time (also called timestamp)
Method (GET or POST)
URI
HTTP status code
User-agent
Additional attributes can usually be included, such as:
Referrer: the URL that ‘linked’ the user to your site
Redirected URL, when a redirect occurs
Size of the file sent (in bytes)
Time taken: the time it takes for a request to be processed and its response to be sent
Why are log files important for SEO?
If you don’t know why they matter, read this. Time spent wisely!
Accessing your log files
If you’re not sure where to start, the best is to ask your (client’s) Web Developer/DevOps if they can grant you access to raw server logs via FTP, ideally without any filtering applied.
Here are the general guidelines to find and manage log data on the three most popular servers:
Apache log files (Linux)
NGINX log files (Linux)
IIS log files (Windows)
We’ll use raw Apache files in this project.
Why Pandas alone is not enough when it comes to log analysis
Pandas (an open-source data manipulation tool built with Python) is pretty ubiquitous in data science.
It’s a must to slice and dice tabular data structures, and the mammal works like a charm when the data fits in memory!
That is, a few gigabytes. But not terabytes.
Parallel computing aside (e.g. Dask, PySpark), a database is usually a better solution for big data tasks that do not fit in memory. With a database, we can work with datasets that consume terabytes of disk space. Everything can be queried (via SQL), accessed, and updated in a breeze!
In this post, we’ll query our raw log data programmatically in Python via Google BigQuery. It’s easy to use, affordable and lightning-fast – even on terabytes of data!
The Python/BigQuery combo also allows you to query files stored on Google Cloud Storage. Sweet!
If Google is a nay-nay for you and you wish to try alternatives, Amazon and Microsoft also offer cloud data warehouses. They integrate well with Python too:
Amazon:
AWS S3
Redshift
Microsoft:
Azure Storage
Azure data warehouse
Azure Synaps
Create a GCP account and set-up Cloud Storage
Both Google Cloud Storage and BigQuery are part of Google Cloud Platform (GCP), Google’s suite of cloud computing services.
GCP is not free, but you can try it for a year with $300 credits, with access to all products. Pretty cool.
Note that once the trial expires, Google Cloud Free Tier will still give you access to most Google Cloud resources, free of charge. With 5 GB of storage per month, it’s usually enough if you want to experiment with small datasets, work on proof of concepts, etc…
Believe me, there are many. Great. Things. To. Try!
You can sign-up for a free trial here.
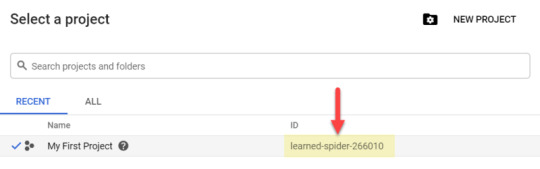
Once you have completed sign-up, a new project will be automatically created with a random, and rather exotic, name – e.g. mine was “learned-spider-266010“!
Create our first bucket to store our log files
In Google Cloud Storage, files are stored in “buckets”. They will contain our log files.
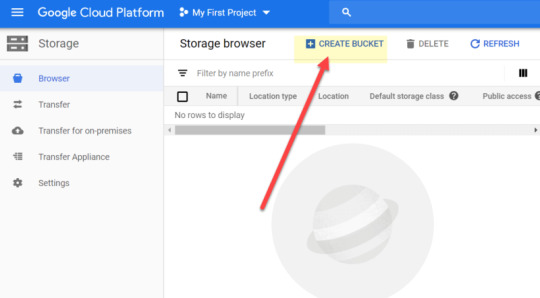
To create your first bucket, go to storage > browser > create bucket:
The bucket name has to be unique. I’ve aptly named mine ‘seo_server_logs’!
We then need to choose where and how to store our log data:
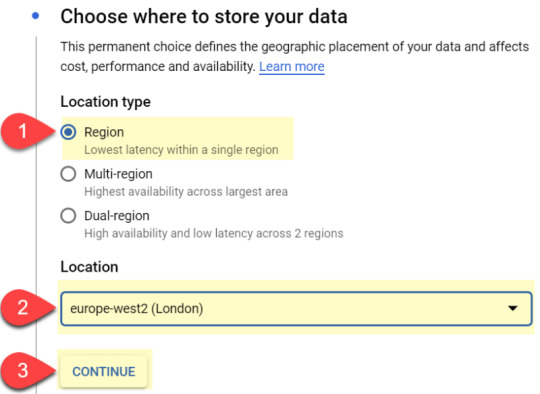
#1 Location type – ‘Region’ is usually good enough.
#2 Location – As I’m based in the UK, I’ve selected ‘Europe-West2’. Select your nearest location
#3 Click on ‘continue’
Default storage class: I’ve had good results with ‘nearline‘. It is cheaper than standard, and the data is retrieved quickly enough:

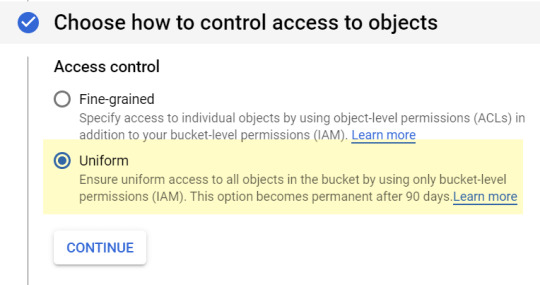
Access to objects: “Uniform” is fine:
Finally, in the “advanced settings” block, select:
#1 – Google-managed key
#2 – No retention policy
#3 – No need to add a label for now
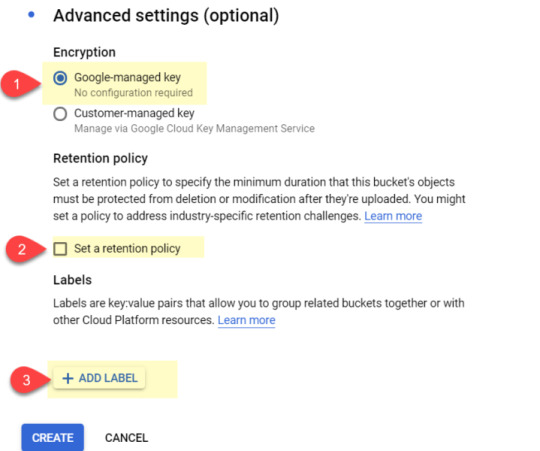
When you’re done, click “‘create.”
You’ve created your first bucket! Time to upload our log data.
Adding log files to your Cloud Storage bucket
You can upload as many files as you wish, whenever you want to!
The simplest way is to drag and drop your files to Cloud Storage’s Web UI, as shown below:

Yet, if you really wanted to get serious about log analysis, I’d strongly suggest automating the data ingestion process!
Here are a few things you can try:
Cron jobs can be set up between FTP servers and Cloud Storage infrastructures:
Gsutil, if on GCP
SFTP Transfers, if on AWS
FTP managers like Cyberduck also offer automatic transfers to storage systems, too
More data ingestion tips here (AppEngine, JSON API etc.)
A quick note on file formats
The sample files uploaded in Github have already been converted to .csv for you.
Bear in mind that you may have to convert your own log files to a compliant file format for SQL querying. Bigquery accepts .csv or .parquet.
Files can easily be bulk-converted to another format via the command line. You can access the command line as follows on Windows:
Open the Windows Start menu
Type “command” in the search bar
Select “Command Prompt” from the search results
I’ve not tried this on a Mac, but I believe the CLI is located in the Utilities folder
Once opened, navigate to the folder containing the files you want to convert via this command:
CD 'path/to/folder’
Simply replace path/to/folder with your path.
Then, type the command below to convert e.g. .log files to .csv:
for file in *.log; do mv "$file" "$(basename "$file" .*0).csv"; done
Note that you may need to enable Windows Subsystem for Linux to use this Bash command.
Now that our log files are in, and in the right format, it’s time to start Pythoning!
Unleash the Python
Do I still need to present Python?!
According to Stack Overflow, Python is now the fastest-growing major programming language. It’s also getting incredibly popular in the SEO sphere, thanks to Python preachers like Hamlet or JR.
You can run Python on your local computer via Jupyter notebook or an IDE, or even in the cloud via Google Colab. We’ll use Google Colab in this article.
Remember, the notebook is here, and the code snippets are pasted below, along with explanations.
Import libraries + GCP authentication
We’ll start by running the cell below:
It imports the Python libraries we need and redirects you to an authentication screen.
There you’ll have to choose the Google account linked to your GCP project.
Connect to Google Cloud Storage (GCS) and BigQuery
There’s quite a bit of info to add in order to connect our Python notebook to GCS & BigQuery. Besides, filling in that info manually can be tedious!
Fortunately, Google Colab’s forms make it easy to parameterize our code and save time.
The forms in this notebook have been pre-populated for you. No need to do anything, although I do suggest you amend the code to suit your needs.
Here’s how to create your own form: Go to Insert > add form field > then fill in the details below:
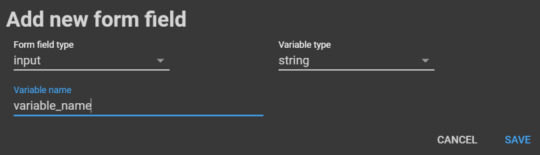
When you change an element in the form, its corresponding values will magically change in the code!
Fill in ‘project ID’ and ‘bucket location’
In our first form, you’ll need to add two variables:
Your GCP PROJECT_ID (mine is ‘learned-spider-266010′)
Your bucket location:
To find it, in GCP go to storage > browser > check location in table
Mine is ‘europe-west2′

Here’s the code snippet for that form:
Fill in ‘bucket name’ and ‘file/folder path’:
In the second form, we’ll need to fill in two more variables:

The bucket name:
To find it, in GCP go to: storage > browser > then check its ‘name’ in the table
I’ve aptly called it ‘apache_seo_logs’!
The file path:
You can use a wildcard to query several files – Very nice!
E.g. with the wildcarded path ‘Loggy*’, Bigquery would query these three files at once:
Loggy01.csv
Loggy02.csv
Loggy03.csv
Bigquery also creates a temporary table for that matter (more on that below)
Here’s the code for the form:
Connect Python to Google Cloud Storage and BigQuery
In the third form, you need to give a name to your BigQuery table – I’ve called mine ‘log_sample’. Note that this temporary table won’t be created in your Bigquery account.
Okay, so now things are getting really exciting, as we can start querying our dataset via SQL *without* leaving our notebook – How cool is that?!
As log data is still in its raw form, querying it is somehow limited. However, we can apply basic SQL filtering that will speed up Pandas operations later on.
I have created 2 SQL queries in this form:
“SQL_1st_Filter” to filter any text
“SQL_Useragent_Filter” to select your User-Agent, via a drop-down
Feel free to check the underlying code and tweak these two queries to your needs.
If your SQL trivia is a bit rusty, here’s a good refresher from Kaggle!
Code for that form:
Converting the list output to a Pandas Dataframe
The output generated by BigQuery is a two-dimensional list (also called ‘list of lists’). We’ll need to convert it to a Pandas Dataframe via this code:
Done! We now have a Dataframe that can be wrangled in Pandas!
Data cleansing time, the Pandas way!
Time to make these cryptic logs a bit more presentable by:
Splitting each element
Creating a column for each element
Split IP addresses
Split dates and times
We now need to convert the date column from string to a “Date time” object, via the Pandas to_datetime() method:
Doing so will allow us to perform time-series operations such as:
Slicing specific date ranges
Resampling time series for different time periods (e.g. from day to month)
Computing rolling statistics, such as a rolling average
The Pandas/Numpy combo is really powerful when it comes to time series manipulation, check out all you can do here!
More split operations below:
Split domains
Split methods (Get, Post etc…)
Split URLs
Split HTTP Protocols
Split status codes
Split ‘time taken’
Split referral URLs
Split User Agents
Split redirected URLs (when existing)
Reorder columns
Time to check our masterpiece:
Well done! With just a few lines of code, you converted a set of cryptic logs to a structured Dataframe, ready for exploratory data analysis.
Let’s add a few more extras.
Create categorical columns
These categorical columns will come handy for data analysis or visualization tasks. We’ll create two, paving the way for your own experiments!
Create an HTTP codes class column
Create a search engine bots category column
As you can see, our new columns httpCodeClass and SEBotClass have been created:

Spotting ‘spoofed’ search engine bots
We still need to tackle one crucial step for SEO: verify that IP addresses are genuinely from Googlebots.
All credit due to the great Tyler Reardon for this bit! Tyler has created searchtools.io, a clever tool that checks IP addresses and returns ‘fake’ Googlebot ones, based on a reverse DNS lookup.
We’ve simply integrated that script into the notebook – code snippet below:
Running the cell above will create a new column called ‘isRealGbot?:

Note that the script is still in its early days, so please consider the following caveats:
You may get errors when checking a huge amount of IP addresses. If so, just bypass the cell
Only Googlebots are checked currently
Tyler and I are working on the script to improve it, so keep an eye on Twitter for future enhancements!
Filter the Dataframe before final export
If you wish to further refine the table before exporting to .csv, here’s your chance to filter out status codes you don’t need and refine timescales.
Some common use cases:
You have 12 months’ worth of log data stored in the cloud, but only want to review the last 2 weeks
You’ve had a recent website migration and want to check all the redirects (301s, 302s, etc.) and their redirect locations
You want to check all 4XX response codes
Filter by date
Refine start and end dates via this form:

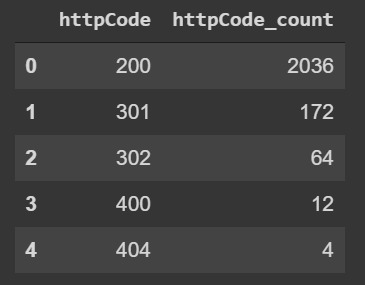
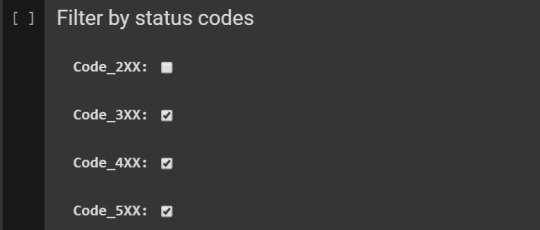
Filter by status codes
Check status codes distribution before filtering:
Code:
Then filter HTTP status codes via this form:
Related code:
Export to .csv
Our last step is to export our Dataframe to a .csv file. Give it a name via the export form:

Code for that last form:
Final words and shout-outs
Pat on the back if you’ve followed till here! You’ve achieved so much over the course of this article!
I cannot wait to take it to the next level in my next column, with more advanced data modeling/visualization techniques!
I’d like to thank the following people:
Tyler Reardon, who’s helped me to integrate his anti-spoofing tool into this notebook!
Paul Adams from Octamis and my dear compatriot Olivier Papon for their expert advice
Last but not least, Kudos to Hamlet Batista or JR Oakes – Thanks guys for being so inspirational to the SEO community!
Please reach me out on Twitter if questions, or if you need further assistance. Any feedback (including pull requests! :)) is also greatly appreciated!
Happy Pythoning!
This year’s SMX Advanced will feature a brand-new SEO for Developers track with highly-technical sessions – many in live-coding format – focused on using code libraries and architecture models to develop applications that improve SEO. SMX Advanced will be held June 8-10 in Seattle. Register today.
The post Leverage Python and Google Cloud to extract meaningful SEO insights from server log data appeared first on Search Engine Land.
Leverage Python and Google Cloud to extract meaningful SEO insights from server log data published first on https://likesandfollowersclub.weebly.com/
0 notes
Text
Leverage Python and Google Cloud to extract meaningful SEO insights from server log data
For my first post on Search Engine Land, I’ll start by quoting Ian Lurie:
Log file analysis is a lost art. But it can save your SEO butt!
Wise words.
However, getting the data we need out of server log files is usually laborious:
Gigantic log files require robust data ingestion pipelines, a reliable cloud storage infrastructure, and a solid querying system
Meticulous data modeling is also needed in order to convert cryptic, raw logs data into legible bits, suitable for exploratory data analysis and visualization
In the first post of this two-part series, I will show you how to easily scale your analyses to larger datasets, and extract meaningful SEO insights from your server logs.
All of that with just a pinch of Python and a hint of Google Cloud!
Here’s our detailed plan of action:
#1 – I’ll start by giving you a bit of context:
What are log files and why they matter for SEO
How to get hold of them
Why Python alone doesn’t always cut it when it comes to server log analysis
#2 – We’ll then set things up:
Create a Google Cloud Platform account
Create a Google Cloud Storage bucket to store our log files
Use the Command-Line to convert our files to a compliant format for querying
Transfer our files to Google Cloud Storage, manually and programmatically
#3 – Lastly, we’ll get into the nitty-gritty of Pythoning – we will:
Query our log files with Bigquery, inside Colab!
Build a data model that makes our raw logs more legible
Create categorical columns that will enhance our analyses further down the line
Filter and export our results to .csv
In part two of this series (available later this year), we’ll discuss more advanced data modeling techniques in Python to assess:
Bot crawl volume
Crawl budget waste
Duplicate URL crawling
I’ll also show you how to aggregate and join log data to Search Console data, and create interactive visualizations with Plotly Dash!
Excited? Let’s get cracking!
System requirements
We will use Google Colab in this article. No specific requirements or backward compatibility issues here, as Google Colab sits in the cloud.
Downloadable files
The Colab notebook can be accessed here
The log files can be downloaded on Github – 4 sample files of 20 MB each, spanning 4 days (1 day per file)
Be assured that the notebook has been tested with several million rows at lightning speed and without any hurdles!
Preamble: What are log files?
While I don’t want to babble too much about what log files are, why they can be invaluable for SEO, etc. (heck, there are many great articles on the topic already!), here’s a bit of context.
A server log file records every request made to your web server for content.
Every. Single. One.
In their rawest forms, logs are indecipherable, e.g. here are a few raw lines from an Apache webserver:

Daunting, isn’t it?
Raw logs must be “cleansed” in order to be analyzed; that’s where data modeling kicks in. But more on that later.
Whereas the structure of a log file mainly depends on the server (Apache, Nginx, IIS etc…), it has evergreen attributes:
Server IP
Date/Time (also called timestamp)
Method (GET or POST)
URI
HTTP status code
User-agent
Additional attributes can usually be included, such as:
Referrer: the URL that ‘linked’ the user to your site
Redirected URL, when a redirect occurs
Size of the file sent (in bytes)
Time taken: the time it takes for a request to be processed and its response to be sent
Why are log files important for SEO?
If you don’t know why they matter, read this. Time spent wisely!
Accessing your log files
If you’re not sure where to start, the best is to ask your (client’s) Web Developer/DevOps if they can grant you access to raw server logs via FTP, ideally without any filtering applied.
Here are the general guidelines to find and manage log data on the three most popular servers:
Apache log files (Linux)
NGINX log files (Linux)
IIS log files (Windows)
We’ll use raw Apache files in this project.
Why Pandas alone is not enough when it comes to log analysis
Pandas (an open-source data manipulation tool built with Python) is pretty ubiquitous in data science.
It’s a must to slice and dice tabular data structures, and the mammal works like a charm when the data fits in memory!
That is, a few gigabytes. But not terabytes.
Parallel computing aside (e.g. Dask, PySpark), a database is usually a better solution for big data tasks that do not fit in memory. With a database, we can work with datasets that consume terabytes of disk space. Everything can be queried (via SQL), accessed, and updated in a breeze!
In this post, we’ll query our raw log data programmatically in Python via Google BigQuery. It’s easy to use, affordable and lightning-fast – even on terabytes of data!
The Python/BigQuery combo also allows you to query files stored on Google Cloud Storage. Sweet!
If Google is a nay-nay for you and you wish to try alternatives, Amazon and Microsoft also offer cloud data warehouses. They integrate well with Python too:
Amazon:
AWS S3
Redshift
Microsoft:
Azure Storage
Azure data warehouse
Azure Synaps
Create a GCP account and set-up Cloud Storage
Both Google Cloud Storage and BigQuery are part of Google Cloud Platform (GCP), Google’s suite of cloud computing services.
GCP is not free, but you can try it for a year with $300 credits, with access to all products. Pretty cool.
Note that once the trial expires, Google Cloud Free Tier will still give you access to most Google Cloud resources, free of charge. With 5 GB of storage per month, it’s usually enough if you want to experiment with small datasets, work on proof of concepts, etc…
Believe me, there are many. Great. Things. To. Try!
You can sign-up for a free trial here.
Once you have completed sign-up, a new project will be automatically created with a random, and rather exotic, name – e.g. mine was “learned-spider-266010“!
Create our first bucket to store our log files
In Google Cloud Storage, files are stored in “buckets”. They will contain our log files.
To create your first bucket, go to storage > browser > create bucket:
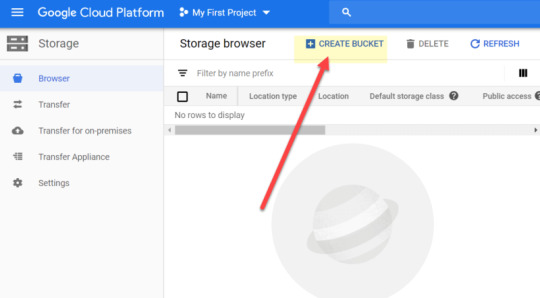
The bucket name has to be unique. I’ve aptly named mine ‘seo_server_logs’!
We then need to choose where and how to store our log data:
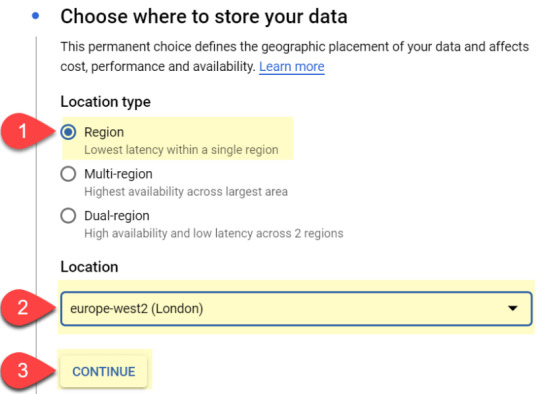
#1 Location type – ‘Region’ is usually good enough.
#2 Location – As I’m based in the UK, I’ve selected ‘Europe-West2’. Select your nearest location
#3 Click on ‘continue’
Default storage class: I’ve had good results with ‘nearline‘. It is cheaper than standard, and the data is retrieved quickly enough:
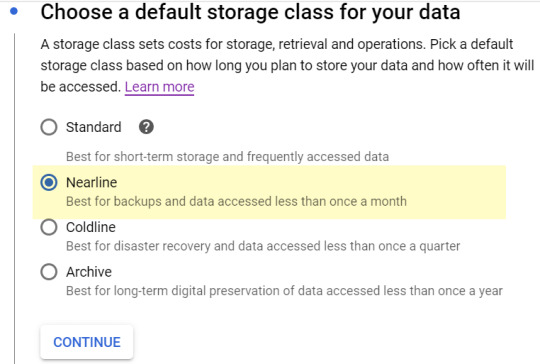
Access to objects: “Uniform” is fine:
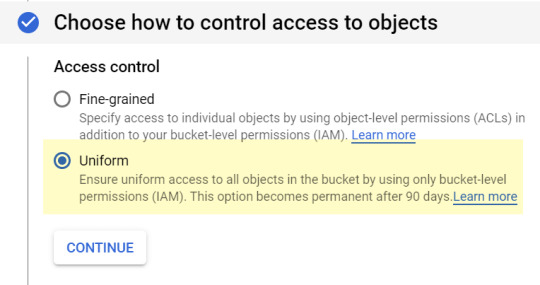
Finally, in the “advanced settings” block, select:
#1 – Google-managed key
#2 – No retention policy
#3 – No need to add a label for now

When you’re done, click “‘create.”
You’ve created your first bucket! Time to upload our log data.
Adding log files to your Cloud Storage bucket
You can upload as many files as you wish, whenever you want to!
The simplest way is to drag and drop your files to Cloud Storage’s Web UI, as shown below:
Yet, if you really wanted to get serious about log analysis, I’d strongly suggest automating the data ingestion process!
Here are a few things you can try:
Cron jobs can be set up between FTP servers and Cloud Storage infrastructures:
Gsutil, if on GCP
SFTP Transfers, if on AWS
FTP managers like Cyberduck also offer automatic transfers to storage systems, too
More data ingestion tips here (AppEngine, JSON API etc.)
A quick note on file formats
The sample files uploaded in Github have already been converted to .csv for you.
Bear in mind that you may have to convert your own log files to a compliant file format for SQL querying. Bigquery accepts .csv or .parquet.
Files can easily be bulk-converted to another format via the command line. You can access the command line as follows on Windows:
Open the Windows Start menu
Type “command” in the search bar
Select “Command Prompt” from the search results
I’ve not tried this on a Mac, but I believe the CLI is located in the Utilities folder
Once opened, navigate to the folder containing the files you want to convert via this command:
CD 'path/to/folder’
Simply replace path/to/folder with your path.
Then, type the command below to convert e.g. .log files to .csv:
for file in *.log; do mv "$file" "$(basename "$file" .*0).csv"; done
Note that you may need to enable Windows Subsystem for Linux to use this Bash command.
Now that our log files are in, and in the right format, it’s time to start Pythoning!
Unleash the Python
Do I still need to present Python?!
According to Stack Overflow, Python is now the fastest-growing major programming language. It’s also getting incredibly popular in the SEO sphere, thanks to Python preachers like Hamlet or JR.
You can run Python on your local computer via Jupyter notebook or an IDE, or even in the cloud via Google Colab. We’ll use Google Colab in this article.
Remember, the notebook is here, and the code snippets are pasted below, along with explanations.
Import libraries + GCP authentication
We’ll start by running the cell below:
It imports the Python libraries we need and redirects you to an authentication screen.
There you’ll have to choose the Google account linked to your GCP project.
Connect to Google Cloud Storage (GCS) and BigQuery
There’s quite a bit of info to add in order to connect our Python notebook to GCS & BigQuery. Besides, filling in that info manually can be tedious!
Fortunately, Google Colab’s forms make it easy to parameterize our code and save time.
The forms in this notebook have been pre-populated for you. No need to do anything, although I do suggest you amend the code to suit your needs.
Here’s how to create your own form: Go to Insert > add form field > then fill in the details below:
When you change an element in the form, its corresponding values will magically change in the code!
Fill in ‘project ID’ and ‘bucket location’
In our first form, you’ll need to add two variables:
Your GCP PROJECT_ID (mine is ‘learned-spider-266010′)
Your bucket location:
To find it, in GCP go to storage > browser > check location in table
Mine is ‘europe-west2′

Here’s the code snippet for that form:
Fill in ‘bucket name’ and ‘file/folder path’:
In the second form, we’ll need to fill in two more variables:

The bucket name:
To find it, in GCP go to: storage > browser > then check its ‘name’ in the table
I’ve aptly called it ‘apache_seo_logs’!
The file path:
You can use a wildcard to query several files – Very nice!
E.g. with the wildcarded path ‘Loggy*’, Bigquery would query these three files at once:
Loggy01.csv
Loggy02.csv
Loggy03.csv
Bigquery also creates a temporary table for that matter (more on that below)
Here’s the code for the form:
Connect Python to Google Cloud Storage and BigQuery
In the third form, you need to give a name to your BigQuery table – I’ve called mine ‘log_sample’. Note that this temporary table won’t be created in your Bigquery account.
Okay, so now things are getting really exciting, as we can start querying our dataset via SQL *without* leaving our notebook – How cool is that?!
As log data is still in its raw form, querying it is somehow limited. However, we can apply basic SQL filtering that will speed up Pandas operations later on.
I have created 2 SQL queries in this form:
“SQL_1st_Filter” to filter any text
“SQL_Useragent_Filter” to select your User-Agent, via a drop-down
Feel free to check the underlying code and tweak these two queries to your needs.
If your SQL trivia is a bit rusty, here’s a good refresher from Kaggle!
Code for that form:
Converting the list output to a Pandas Dataframe
The output generated by BigQuery is a two-dimensional list (also called ‘list of lists’). We’ll need to convert it to a Pandas Dataframe via this code:
Done! We now have a Dataframe that can be wrangled in Pandas!
Data cleansing time, the Pandas way!
Time to make these cryptic logs a bit more presentable by:
Splitting each element
Creating a column for each element
Split IP addresses
Split dates and times
We now need to convert the date column from string to a “Date time” object, via the Pandas to_datetime() method:
Doing so will allow us to perform time-series operations such as:
Slicing specific date ranges
Resampling time series for different time periods (e.g. from day to month)
Computing rolling statistics, such as a rolling average
The Pandas/Numpy combo is really powerful when it comes to time series manipulation, check out all you can do here!
More split operations below:
Split domains
Split methods (Get, Post etc…)
Split URLs
Split HTTP Protocols
Split status codes
Split ‘time taken’
Split referral URLs
Split User Agents
Split redirected URLs (when existing)
Reorder columns
Time to check our masterpiece:
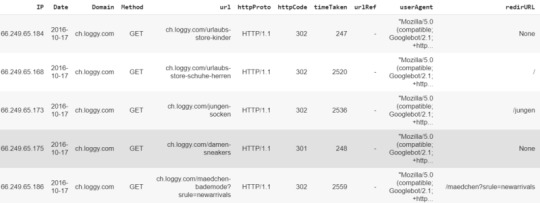
Well done! With just a few lines of code, you converted a set of cryptic logs to a structured Dataframe, ready for exploratory data analysis.
Let’s add a few more extras.
Create categorical columns
These categorical columns will come handy for data analysis or visualization tasks. We’ll create two, paving the way for your own experiments!
Create an HTTP codes class column
Create a search engine bots category column
As you can see, our new columns httpCodeClass and SEBotClass have been created:

Spotting ‘spoofed’ search engine bots
We still need to tackle one crucial step for SEO: verify that IP addresses are genuinely from Googlebots.
All credit due to the great Tyler Reardon for this bit! Tyler has created searchtools.io, a clever tool that checks IP addresses and returns ‘fake’ Googlebot ones, based on a reverse DNS lookup.
We’ve simply integrated that script into the notebook – code snippet below:
Running the cell above will create a new column called ‘isRealGbot?:
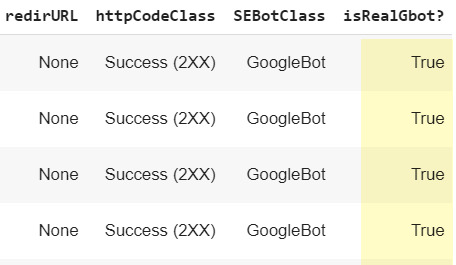
Note that the script is still in its early days, so please consider the following caveats:
You may get errors when checking a huge amount of IP addresses. If so, just bypass the cell
Only Googlebots are checked currently
Tyler and I are working on the script to improve it, so keep an eye on Twitter for future enhancements!
Filter the Dataframe before final export
If you wish to further refine the table before exporting to .csv, here’s your chance to filter out status codes you don’t need and refine timescales.
Some common use cases:
You have 12 months’ worth of log data stored in the cloud, but only want to review the last 2 weeks
You’ve had a recent website migration and want to check all the redirects (301s, 302s, etc.) and their redirect locations
You want to check all 4XX response codes
Filter by date
Refine start and end dates via this form:

Filter by status codes
Check status codes distribution before filtering:
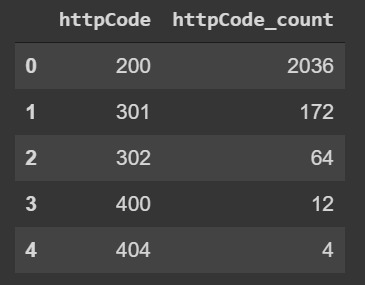
Code:
Then filter HTTP status codes via this form:
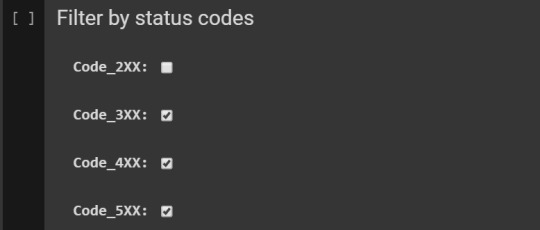
Related code:
Export to .csv
Our last step is to export our Dataframe to a .csv file. Give it a name via the export form:

Code for that last form:
Final words and shout-outs
Pat on the back if you’ve followed till here! You’ve achieved so much over the course of this article!
I cannot wait to take it to the next level in my next column, with more advanced data modeling/visualization techniques!
I’d like to thank the following people:
Tyler Reardon, who’s helped me to integrate his anti-spoofing tool into this notebook!
Paul Adams from Octamis and my dear compatriot Olivier Papon for their expert advice
Last but not least, Kudos to Hamlet Batista or JR Oakes – Thanks guys for being so inspirational to the SEO community!
Please reach me out on Twitter if questions, or if you need further assistance. Any feedback (including pull requests! :)) is also greatly appreciated!
Happy Pythoning!
This year’s SMX Advanced will feature a brand-new SEO for Developers track with highly-technical sessions – many in live-coding format – focused on using code libraries and architecture models to develop applications that improve SEO. SMX Advanced will be held June 8-10 in Seattle. Register today.
The post Leverage Python and Google Cloud to extract meaningful SEO insights from server log data appeared first on Search Engine Land.
Leverage Python and Google Cloud to extract meaningful SEO insights from server log data published first on https://likesfollowersclub.tumblr.com/
0 notes
Text
Customer Convos: The Google Cloud Team

This piece is a part of our Customer Convos series. We’re sharing stories of how people use npm at work. Want to share your thoughts? Drop us a line.
Q: Hi! Can you state your name and what you do, and what your company does?
Luke Sneeringer, SWE: Our company is Google.
How about this: what specifically are you doing? What does your team do?
LS: I am responsible for the authorship and maintenance of cloud client libraries in Python in Node.js.
Justin Beckwith, Product Manager: Essentially, Google has over 100 APIs and services that we provide to developers, and for each of those APIs and services we have a set of libraries we use to access them. The folks on this team help build the client libraries. Some libraries are automatically generated while others are hand-crafted, but for each API service that Google has, we want to have a corresponding npm module that makes it easy and delightful for Node.js users to use.
How’s your day going?
JB: My day’s going awesome! We’re at a Node conference, the best time of the year. You get to see all your friends and hang out with people that you only get to see here at Node.js Interactive and at Node Summit.
Today, we announced the public beta of Firestore, and of course we published an npm package. Cloud Firestore is a fully-managed NoSQL database, designed to easily store and sync app data at global scale.
Tell me the story of npm at your company. What specific problem did you have that private packages and Orgs solved?
JB: Google is a large company with a lot of products that span a lot of different spaces, but we want to have a single, consistent way for all of our developers to be able to publish their packages. More importantly, we need to have some sort of organizational mesh for the maintenance of those packages. For instance, if Ali publishes a package one day, and then tomorrow he leaves Google, we need to make sure we have the appropriate organization in place so that multiple people have the right access.
Ali Shiekh, SWE: We use npm Organization features to manage our modules and have teams set up to manage each of the distinct libraries that we have.
JB: We’re also users of some of the metrics that y’all produce. We use the number of daily installs for each module to measure adoption of our libraries and to figure out how they’re performing, not only against other npm modules but also other languages we support on the platform.
How do you consume that? Just logging into the website?
JB: No, we do a HTTP call, grab the response, and put it into BigQuery. Then we do analytics over that data in BigQuery and have it visualized on our dashboards.
How can private packages and orgs help you out?
JB: At Google, any time we release a product, there are four release phases that we go through, and the first is what we call an EAP, which is an “Early Access Preview” for a few hundred customers. When we’re distributing those EAPs, it can be difficult to get packages in the hands of customers. We don’t want to disclose a product that’s coming out, because we haven’t announced it yet, but we still need validation and feedback from people that we’ve built the right API and we have the right thing. Moving forward, that’s the way we’d like to use private packages.
What’s an improvement on our side that you would like to see? Or something you would like to see in the future?
LS: Something that we would be interested in seeing npm develop is the ability to have certain versions of a public package be private. Let’s say that we have 1.0, and there’s a 2.0 being developed in private that’s being EAP’ed.… I don’t think you have the concept yet of a private version of a public package.
Along with that, better management of package privacy. Managing an EAP for five people is very different than managing an EAP for 300 people. Another thing that would be nice would be the ability to give another npm Org access to a module at once.
AS: The user interface for Org controls and access management of teams within orgs seems a bit not fully defined at this point. Getting some of that management of Orgs in the UI would be a lot nicer. Before Orgs existed, we had a lot of modules that were published without Orgs, and getting them added to the org is fairly complicated because you have to go through a support ticket to get that done.
JB: Until this morning, you want to know what my first answer would have been?
2FA?
JB: 2FA! Yes.
LS: Also, Fido U2F, please. That is the standard behind security keys.
Would you recommend that another organization use npm Orgs?
JB: Well, yes, and also, it’s a provocative question… is there an alternative?
LS: I was going to say; you’re the only game in town.
Any other cool stuff you’d like to promote?
JB: The Firestore launch, of course, but another thing is the Google Stackdriver Debugger agent. We released this service called Stackdriver Debugger that lets you do passive debugging in production. You push your code to App Engine, or Kubernetes, or Compute engine. While it’s running, you can set breakpoints, and when that code gets hit, it will take a snapshot and visualize that without blocking the request. It’s a passive production debugger.
Did you just ‘one more thing’ us there? ‘Oh also, check out this amazing thing’!
JB: It’s kind of dark magic, actually. It’s a little ridiculous.
2 notes
·
View notes
Text
I Found This Interesting. Joshua Damien Cordle
Google Presents a Cornucopia of Cloud Goodies
By Richard Adhikari

Google announced a host of new services, features and partners at Google Cloud Next '19 Day 2 in San Francisco on Wednesday.
The new unveilings followed its announcement of Anthos, an open source platform powered by Kubernetes, on Day 1.
Anthos is "a single platform for developers and operations; it is for on-premise and multicloud installations," Urs Hölzle, Google's senior vice president, technical infrastructure, told the audience Wednesday. "With Anthos we're making hybrid and multicloud the new normal."
Open Standards Vision
Hölzle announced the following new tools:
Traffic Director, a fully managed control plane for service meshes, which uses open standard APIs;
Cloud Run, a managed compute platform built on theKnative open source project, which lets users run stateless containers invocable through HTTP requests;
Cloud Security Command Center;
The beta of Event Threat Detection, a service that will let users spot signs of compromise or malicious activity in their logs;
The alpha of Policy Intelligence, a machine language-based service that ensures that users access the right set of policy controls; and
A software security key in beta that Hölzle said works in most Android phones.
The new features "are part of a larger single vision of a cloud platform built around open standards with commitment to uptime and reliability," Hölzle noted.
"The key here is helping customers start their cloud journey," observed Ray Wang, principal analyst at Constellation Research.
"SAP workloads, AI/ML, security, and data center availability are huge," he told TechNewsWorld. "G Suite is also growing, with 5 million paid users, up from 4 million last year."
Google also announced 30 security features that are "part of a larger single vision of a cloud platform built around open standards with commitment to uptime and reliability," Hölzle said.
On the whole, Google is just playing catch-up, Wang said. "They basically started Day 1 by saying 'We know we may have been behind for the past three years, but we're back now and these are the features we should have had and they're now available."
Data Management
Among Google's Wednesday announcements was a data management plan to move Microsoft customers to the Google Cloud.
Deepti Srivastava, Google's product manager, cloud databases, introduced the following:
Cloud SQL for Microsoft SQL Server, a fully managed service coming later this year; and
A managed service for Microsoft Active Directory that will run actual Active Directory domain controllers, also coming later this year.
In the area of analytics, Google unveiled Smart Analytics, which will let customers "use AI models and ML to automatically categorize data for business analysts' use," Google Cloud CEO Thomas Kurian said. It will include new features to make it easier to move data into the Google Cloud.
Julie Price, Google big data specialist and cloud customer engineer, announced AutoML Tables, which lets users automatically build and deploy AI tables without expertise in SQL or writing code.
When used with the BigQuery BI Engine now in beta and Connected Sheets, a new G Suite feature that can handle billions of records, AutoML Tables allows customers to turn data into mission-critical insights and predictions.
Google is "known for search, which gives them the best opportunity with data analytics," noted Rob Enderle, principal analyst at the Enderle Group.
However, "concerns about its security and funding model will likely significantly reduce what otherwise would be strong sales in what's perceived to be its strongest skill set," he told TechNewsWorld.
Revamping the G Suite for the Enterprise
Amy Lokey, VP of user experience for G Suite, said AI built into G Suite now lets Google Assistant access applications and interact with users. For example, a user who was running late for a meeting could notify other participants and ask them to save a seat.
Google has brought Hangouts Chat into Gmail, and provided third-party connectivity in Cloud Search, letting users search in SAP, Salesforce and SharePoint.
AI and the Cloud
Rajen Sheth, Google's director, product management, cloud AI, announced the AI Platform, comprised of Kubeflow; the AI Hub, a "one-stop shop for all your AI resources"; and three AI products for business decision makers, including Contact Center AI.
"We're integrating Contact Center AI into our ecosystem," Sarah Patterson, Salesforce's SVP of product marketing and strategy, told the audience.
Industry-Specific Solutions
Google has partnered with a number of companies to build industry-specific solutions.
For example, it has been working with the auto and gaming industries to leverage GEO for location-based capabilities. It also has partnerships in the healthcare industry and in telco, media and entertainment, through its partnership with Accenture on Intelligent Customer Engagement Solutions.
Google's Contact Center AI, in combination with telephony vendors, "provides the underlying framework for AI-powered interactions and agent assist," said Arnab Chakraborty, Accenture's managing director, applied intelligence.
"Accenture will provide the industry-specific dialog design creation and knowledge model curation, which is the content that runs on CCAI," he told TechNewsWorld. "Our solution will be built on top of and around, existing solutions."
On the hardware side, the Google Cloud Platform is the first cloud instance to offer Nvidia Virtual Quadro Workstation on the Nvidia T4, Nvidia spokesperson Gail Laguna told TechNewsWorld, noting that GPU-accelerated containers from Nvidia GPU Cloud are "used thousands of times a month by Google Cloud users."
0 notes
Text
Google Cloud’s BigQuery Autonomous Data To AI Platform

BigQuery automates data analysis, transformation, and insight generation using AI. AI and natural language interaction simplify difficult operations.
The fast-paced world needs data access and a real-time data activation flywheel. Artificial intelligence that integrates directly into the data environment and works with intelligent agents is emerging. These catalysts open doors and enable self-directed, rapid action, which is vital for success. This flywheel uses Google's Data & AI Cloud to activate data in real time. BigQuery has five times more organisations than the two leading cloud providers that just offer data science and data warehousing solutions due to this emphasis.
Examples of top companies:
With BigQuery, Radisson Hotel Group enhanced campaign productivity by 50% and revenue by over 20% by fine-tuning the Gemini model.
By connecting over 170 data sources with BigQuery, Gordon Food Service established a scalable, modern, AI-ready data architecture. This improved real-time response to critical business demands, enabled complete analytics, boosted client usage of their ordering systems, and offered staff rapid insights while cutting costs and boosting market share.
J.B. Hunt is revolutionising logistics for shippers and carriers by integrating Databricks into BigQuery.
General Mills saves over $100 million using BigQuery and Vertex AI to give workers secure access to LLMs for structured and unstructured data searches.
Google Cloud is unveiling many new features with its autonomous data to AI platform powered by BigQuery and Looker, a unified, trustworthy, and conversational BI platform:
New assistive and agentic experiences based on your trusted data and available through BigQuery and Looker will make data scientists, data engineers, analysts, and business users' jobs simpler and faster.
Advanced analytics and data science acceleration: Along with seamless integration with real-time and open-source technologies, BigQuery AI-assisted notebooks improve data science workflows and BigQuery AI Query Engine provides fresh insights.
Autonomous data foundation: BigQuery can collect, manage, and orchestrate any data with its new autonomous features, which include native support for unstructured data processing and open data formats like Iceberg.
Look at each change in detail.
User-specific agents
It believes everyone should have AI. BigQuery and Looker made AI-powered helpful experiences generally available, but Google Cloud now offers specialised agents for all data chores, such as:
Data engineering agents integrated with BigQuery pipelines help create data pipelines, convert and enhance data, discover anomalies, and automate metadata development. These agents provide trustworthy data and replace time-consuming and repetitive tasks, enhancing data team productivity. Data engineers traditionally spend hours cleaning, processing, and confirming data.
The data science agent in Google's Colab notebook enables model development at every step. Scalable training, intelligent model selection, automated feature engineering, and faster iteration are possible. This agent lets data science teams focus on complex methods rather than data and infrastructure.
Looker conversational analytics lets everyone utilise natural language with data. Expanded capabilities provided with DeepMind let all users understand the agent's actions and easily resolve misconceptions by undertaking advanced analysis and explaining its logic. Looker's semantic layer boosts accuracy by two-thirds. The agent understands business language like “revenue” and “segments” and can compute metrics in real time, ensuring trustworthy, accurate, and relevant results. An API for conversational analytics is also being introduced to help developers integrate it into processes and apps.
In the BigQuery autonomous data to AI platform, Google Cloud introduced the BigQuery knowledge engine to power assistive and agentic experiences. It models data associations, suggests business vocabulary words, and creates metadata instantaneously using Gemini's table descriptions, query histories, and schema connections. This knowledge engine grounds AI and agents in business context, enabling semantic search across BigQuery and AI-powered data insights.
All customers may access Gemini-powered agentic and assistive experiences in BigQuery and Looker without add-ons in the existing price model tiers!
Accelerating data science and advanced analytics
BigQuery autonomous data to AI platform is revolutionising data science and analytics by enabling new AI-driven data science experiences and engines to manage complex data and provide real-time analytics.
First, AI improves BigQuery notebooks. It adds intelligent SQL cells to your notebook that can merge data sources, comprehend data context, and make code-writing suggestions. It also uses native exploratory analysis and visualisation capabilities for data exploration and peer collaboration. Data scientists can also schedule analyses and update insights. Google Cloud also lets you construct laptop-driven, dynamic, user-friendly, interactive data apps to share insights across the organisation.
This enhanced notebook experience is complemented by the BigQuery AI query engine for AI-driven analytics. This engine lets data scientists easily manage organised and unstructured data and add real-world context—not simply retrieve it. BigQuery AI co-processes SQL and Gemini, adding runtime verbal comprehension, reasoning skills, and real-world knowledge. Their new engine processes unstructured photographs and matches them to your product catalogue. This engine supports several use cases, including model enhancement, sophisticated segmentation, and new insights.
Additionally, it provides users with the most cloud-optimized open-source environment. Google Cloud for Apache Kafka enables real-time data pipelines for event sourcing, model scoring, communications, and analytics in BigQuery for serverless Apache Spark execution. Customers have almost doubled their serverless Spark use in the last year, and Google Cloud has upgraded this engine to handle data 2.7 times faster.
BigQuery lets data scientists utilise SQL, Spark, or foundation models on Google's serverless and scalable architecture to innovate faster without the challenges of traditional infrastructure.
An independent data foundation throughout data lifetime
An independent data foundation created for modern data complexity supports its advanced analytics engines and specialised agents. BigQuery is transforming the environment by making unstructured data first-class citizens. New platform features, such as orchestration for a variety of data workloads, autonomous and invisible governance, and open formats for flexibility, ensure that your data is always ready for data science or artificial intelligence issues. It does this while giving the best cost and decreasing operational overhead.
For many companies, unstructured data is their biggest untapped potential. Even while structured data provides analytical avenues, unique ideas in text, audio, video, and photographs are often underutilised and discovered in siloed systems. BigQuery instantly tackles this issue by making unstructured data a first-class citizen using multimodal tables (preview), which integrate structured data with rich, complex data types for unified querying and storage.
Google Cloud's expanded BigQuery governance enables data stewards and professionals a single perspective to manage discovery, classification, curation, quality, usage, and sharing, including automatic cataloguing and metadata production, to efficiently manage this large data estate. BigQuery continuous queries use SQL to analyse and act on streaming data regardless of format, ensuring timely insights from all your data streams.
Customers utilise Google's AI models in BigQuery for multimodal analysis 16 times more than last year, driven by advanced support for structured and unstructured multimodal data. BigQuery with Vertex AI are 8–16 times cheaper than independent data warehouse and AI solutions.
Google Cloud maintains open ecology. BigQuery tables for Apache Iceberg combine BigQuery's performance and integrated capabilities with the flexibility of an open data lakehouse to link Iceberg data to SQL, Spark, AI, and third-party engines in an open and interoperable fashion. This service provides adaptive and autonomous table management, high-performance streaming, auto-AI-generated insights, practically infinite serverless scalability, and improved governance. Cloud storage enables fail-safe features and centralised fine-grained access control management in their managed solution.
Finaly, AI platform autonomous data optimises. Scaling resources, managing workloads, and ensuring cost-effectiveness are its competencies. The new BigQuery spend commit unifies spending throughout BigQuery platform and allows flexibility in shifting spend across streaming, governance, data processing engines, and more, making purchase easier.
Start your data and AI adventure with BigQuery data migration. Google Cloud wants to know how you innovate with data.
#technology#technews#govindhtech#news#technologynews#BigQuery autonomous data to AI platform#BigQuery#autonomous data to AI platform#BigQuery platform#autonomous data#BigQuery AI Query Engine
2 notes
·
View notes
Link
À l’occasion de la Cloud Next Conference, cette semaine, Google a annoncé de nouveaux produits et services d’intelligence artificielle proposés dans le cadre de la sortie d’une nouvelle version d’AutoML, et surtout du lancement d'”AI Hub”, sa plateforme d’intelligence artificielle que nous vous présentions en novembre 2018.
AI Hub, la plateforme d’intelligence artificielle de Google
Destiné aux développeurs, data scientists et data engineers, AI Hub permet de créer des modèles d’IA, de les tester et de les déployer. Google avait dévoilé AI Hub en novembre dernier et la présentait comme un centre d’Intelligence Artificielle sécurisé regroupant d’une part un ensemble de ressources de ML développées par les équipes Google, et donnant d’autre part la possibilité aux entreprises de partager des ressources privées en interne. La plateforme propose des “briques” de Machine Learning destinées à des applications telles que la classification, la reconnaissance d’objets ou encore l’extraction d’entités et est interopérable avec AutoML et Cloud Machine Learning.
Consultez sa présentation détaillée.
Mise à jour d’AutoML
D’autres nouveautés ont été présentées au cours de la conférence. Les fonctionnalités beta ajoutées par la mise à jour d’AutoML sont :
AutoML Tables (beta) : AutoML Tables permet de générer et alimenter des modèles AutoML directement depuis des bases BigQuery.
AutoML Video Intelligence (beta) AutoML Video Intelligence permet la classification et l’étiquetage automatique de vidéos.
AutoML Vision, AutoML Vision Edge (beta) AutoML Vision propose des fonctionnalités de détection d’objets en exécution dans le Cloud comme en edge (localement). La position des objets détectés et leur contexte dans l’image est désormais pris en compte.
AutoML Natural Language AutoML Natural Language permet désormais l’extraction personnalisée d’entitées et l’analyse personnalisée de sentiments.
Facilitation de la transformation numérique des entreprises
Autre annonce, celle de la mise à disposition, en version bêta, du service Document Understanding AI. Celui-ci permet de classer, extraire et structurer les données présentes dans des documents informatiques aussi bien que dans des documents papier scannés.
Selon Levent Besik, cette fonctionnalité est destinée à faciliter la transformation numérique des sociétés, qui pour beaucoup, croulent sous des cartons d’archives papier. Le service est compatible avec les solutions des partenaires : Iron Mountain, DocuSign, Uipath, Accenture, Taulia Box et Egnyteya.
Automatisation partielle du support client
Google Cloud Contact Center AI permet d’automatiser partiellement le support client. Cette solution multicanale (destinée au chat et aux centres d’appels) est capable de prendre en charge les questions les plus simples et de laisser répondre les agents de support client aux autres. Si l’interventin d’un agent est requise, l’intelligence artificielle lui suggère des documents de référence issus de la base de connaissance. La création de scénarios repose sur DialogFlow.
TensorFlow 2.0
Les nouveautés de TensorFlow 2.0 ont également été présentées. L’une des modifications est la possibilité de choisir entre le mode eager et le mode graphique. N’hésitez pas à suivre la formation à TensorFlow 2.0 proposée par Thibault Neveu pour en savoir plus sur TensorFlow 2.0 (attention, la formation, d’une durée totale de 5H, est destinée à un public débutant).
Pierre-yves Gerlat

Source: Actu IA
0 notes
Text
Google launches an end-to-end AI platform
As expected, Google used the second day of its annual Cloud Next conference to shine a spotlight on its AI tools. The company made a dizzying number of announcements today, but at the core of all of these new tools and services is the company’s plan to democratize AI and machine learning with pre-built models and easier to use services, while also giving more advanced developers the tools to build their own custom models.
The highlight of today’s announcements is the beta launch of the company’s AI Platform. The idea here is to offer developers and data scientists an end-to-end service for building, testing and deploying their own models. To do this, the service brings together a variety of existing and new products that allow you to build a full data pipeline to pull in data, label it (with the help of a new built-in labeling service) and then either use existing classification, object recognition or entity extraction models, or use existing tools like AutoML or the Cloud Machine Learning engine to train and deploy custom models.
“The AI Platform is this place where, if you are taking this terrifying journey from a journeyman idea of how you can use AI in your enterprise, all the way through launch and a safe, reliable deployment, the AI Platform help you move between each of these stages in a safe way so that you can start with exploratory data analysis, start to build models using your data scientists, decide that you want to use this specific model, and then with essentially one click be able to deploy it,” a Google spokesperson said during a press conference ahead of today’s official announcement.
But there is plenty more AI news, too, mostly courtesy of Cloud AutoML, Google’s tool for automating the model training process for developers with limited machine learning expertise.
One of these new features is AutoML Tables, which takes existing tabular data that may sit in Google’s BigQuery database or in a storage service and automatically creates a model that will predict the value of a given column.
Also new is AutoML Video Intelligence (now in beta), which can automatically annotate and tag video, using object recognition to classify video content and make it searchable. For detecting objects in photos, Google also today launched the beta of AutoML Vision and for applications that run at the edge, Google launched the beta AutoML Vision Edge, which includes the ability to then deploy these models to edge devices.
A lot of enterprise data comes in the form of straightforward, unstructured text, though. For these use cases, Google today launched the betas of its custom entity extraction service and a custom sentiment analysis service. Both of these tools can be customized to fit the needs of a given organization. It’s one thing to use a generic entity extraction service to understand documents, but for most businesses, the real value here is to be able to pull out information that may be very specific to their needs and processes.
Talking about documents, Google also today announced the beta of its Document Understanding API. This is a new platform that can automatically analyze scanned or digital documents. The service basically combines the ability to turn a scanned page into machine-readable text and then use Google’s other machine learning services to extract data from it.
After introducing it in preview last year, the company also today launched the beta of its Contact Center AI. This service, which was built with partners like Twilio, Vonage, Cisco, Five9, Genesys and Mitel, offers a full contact center AI solution that uses tools like Dialogflow and Google’s text-to-speech capabilities to allow its users to build a virtual agent system (and when things go awry, it can pass the customer to a human agent).
It’s no secret that many enterprises struggle to combine all of these tools and services into a coherent platform for their own needs. Maybe it’s no surprise then that Google also today launched it first AI solution for a specific vertical: Google Cloud Retail. This service combines the company’s Vision Product Search, Recommendations AI and AutoML Tables into a single solution for tackling retail use cases. Chances are, we will see more of the packages for other verticals in the near future.
0 notes
Text
Google launches an end-to-end AI platform
As expected, Google used the second day of its annual Cloud Next conference to shine a spotlight on its AI tools. The company made a dizzying number of announcements today, but at the core of all of these new tools and services is the company’s plan to democratize AI and machine learning with pre-built models and easier to use services, while also giving more advanced developers the tools to build their own custom models.
The highlight of today’s announcements is the beta launch of the company’s AI Platform. The idea here is to offer developers and data scientists an end-to-end service for building, testing and deploying their own models. To do this, the service brings together a variety of existing and new products that allow you to build a full data pipeline to pull in data, label it (with the help of a new built-in labeling service) and then either use existing classification, object recognition or entity extraction models, or use existing tools like AutoML or the Cloud Machine Learning engine to train and deploy custom models.
“The AI Platform is this place where, if you are taking this terrifying journey from a journeyman idea of how you can use AI in your enterprise, all the way through launch and a safe, reliable deployment, the AI Platform help you move between each of these stages in a safe way so that you can start with exploratory data analysis, start to build models using your data scientists, decide that you want to use this specific model, and then with essentially one click be able to deploy it,” a Google spokesperson said during a press conference ahead of today’s official announcement.
But there is plenty more AI news, too, mostly courtesy of Cloud AutoML, Google’s tool for automating the model training process for developers with limited machine learning expertise.
One of these new features is AutoML Tables, which takes existing tabular data that may sit in Google’s BigQuery database or in a storage service and automatically creates a model that will predict the value of a given column.
Also new is AutoML Video Intelligence (now in beta), which can automatically annotate and tag video, using object recognition to classify video content and make it searchable. For detecting objects in photos, Google also today launched the beta of AutoML Vision and for applications that run at the edge, Google launched the beta AutoML Vision Edge, which includes the ability to then deploy these models to edge devices.
A lot of enterprise data comes in the form of straightforward, unstructured text, though. For these use cases, Google today launched the betas of its custom entity extraction service and a custom sentiment analysis service. Both of these tools can be customized to fit the needs of a given organization. It’s one thing to use a generic entity extraction service to understand documents, but for most businesses, the real value here is to be able to pull out information that may be very specific to their needs and processes.
Talking about documents, Google also today announced the beta of its Document Understanding API. This is a new platform that can automatically analyze scanned or digital documents. The service basically combines the ability to turn a scanned page into machine-readable text and then use Google’s other machine learning services to extract data from it.
After introducing it in preview last year, the company also today launched the beta of its Contact Center AI. This service, which was built with partners like Twilio, Vonage, Cisco, Five9, Genesys and Mitel, offers a full contact center AI solution that uses tools like Dialogflow and Google’s text-to-speech capabilities to allow its users to build a virtual agent system (and when things go awry, it can pass the customer to a human agent).
It’s no secret that many enterprises struggle to combine all of these tools and services into a coherent platform for their own needs. Maybe it’s no surprise then that Google also today launched it first AI solution for a specific vertical: Google Cloud Retail. This service combines the company’s Vision Product Search, Recommendations AI and AutoML Tables into a single solution for tackling retail use cases. Chances are, we will see more of the packages for other verticals in the near future.
source https://techcrunch.com/2019/04/10/google-expands-its-ai-services/
0 notes
Text
Google launches an end-to-end AI platform
As expected, Google used the second day of its annual Cloud Next conference to shine a spotlight on its AI tools. The company made a dizzying number of announcements today, but at the core of all of these new tools and services is the company’s plan to democratize AI and machine learning with pre-built models and easier to use services, while also giving more advanced developers the tools to build their own custom models.
The highlight of today’s announcements is the beta launch of the company’s AI Platform. The idea here is to offer developers and data scientists an end-to-end service for building, testing and deploying their own models. To do this, the service brings together a variety of existing and new products that allow you to build a full data pipeline to pull in data, label it (with the help of a new built-in labeling service) and then either use existing classification, object recognition or entity extraction models, or use existing tools like AutoML or the Cloud Machine Learning engine to train and deploy custom models.
“The AI Platform is this place where, if you are taking this terrifying journey from a journeyman idea of how you can use AI in your enterprise, all the way through launch and a safe, reliable deployment, the AI Platform help you move between each of these stages in a safe way so that you can start with exploratory data analysis, start to build models using your data scientists, decide that you want to use this specific model, and then with essentially one click be able to deploy it,” a Google spokesperson said during a press conference ahead of today’s official announcement.
But there is plenty more AI news, too, mostly courtesy of Cloud AutoML, Google’s tool for automating the model training process for developers with limited machine learning expertise.
One of these new features is AutoML Tables, which takes existing tabular data that may sit in Google’s BigQuery database or in a storage service and automatically creates a model that will predict the value of a given column.
Also new is AutoML Video Intelligence (now in beta), which can automatically annotate and tag video, using object recognition to classify video content and make it searchable. For detecting objects in photos, Google also today launched the beta of AutoML Vision and for applications that run at the edge, Google launched the beta AutoML Vision Edge, which includes the ability to then deploy these models to edge devices.
A lot of enterprise data comes in the form of straightforward, unstructured text, though. For these use cases, Google today launched the betas of its custom entity extraction service and a custom sentiment analysis service. Both of these tools can be customized to fit the needs of a given organization. It’s one thing to use a generic entity extraction service to understand documents, but for most businesses, the real value here is to be able to pull out information that may be very specific to their needs and processes.
Talking about documents, Google also today announced the beta of its Document Understanding API. This is a new platform that can automatically analyze scanned or digital documents. The service basically combines the ability to turn a scanned page into machine-readable text and then use Google’s other machine learning services to extract data from it.
After introducing it in preview last year, the company also today launched the beta of its Contact Center AI. This service, which was built with partners like Twilio, Vonage, Cisco, Five9, Genesys and Mitel, offers a full contact center AI solution that uses tools like Dialogflow and Google’s text-to-speech capabilities to allow its users to build a virtual agent system (and when things go awry, it can pass the customer to a human agent).
It’s no secret that many enterprises struggle to combine all of these tools and services into a coherent platform for their own needs. Maybe it’s no surprise then that Google also today launched it first AI solution for a specific vertical: Google Cloud Retail. This service combines the company’s Vision Product Search, Recommendations AI and AutoML Tables into a single solution for tackling retail use cases. Chances are, we will see more of the packages for other verticals in the near future.
Via Frederic Lardinois https://techcrunch.com
0 notes
Text
"What a week! 105 announcements from Google Cloud Next '18"
Google Cloud Next ‘18 was incredible! From fantastickeynotes and fireside chats to GO-JEK CTO Ajey Gore appearing on-stage on a scooter to listening to Target CIO Mike McNamara we had an inspiring, educational and entertaining week at our flagship conference. We were joined by over 23,000 leaders, developers and partners from our Google Cloud community, listened to more than 290 customer speakers share their stories of business transformation in the cloud and took part in hundreds of breakout sessions. The theme of the conference was Made Here Together, and we’re so grateful to everyone who attended and contributed to help build the cloud for everyone.
But the week of Next wouldn’t be complete without a comprehensive list of what happened. So without further ado, here are 105 product and solution launches, customer stories and announcements from Next ‘18.
Customers
eBay—The world’s largest global marketplace is leveraging Google Cloud in many different ways, including experimenting with conversational commerce with Google Assistant, building ML models with Cloud TPUs for image classification, and applying AI to help buyers quickly find what they’re looking for.
GO-JEK—This ride-hailing and logistics startup in Jakarta uses Google Cloud to support its hundreds of thousands of concurrent transactions, Maps for predicting traffic and BigQuery to get data insights.
Lahey Health—Lahey’s journey to the cloud included migrating from four legacy email systems to G Suite in 91 days.
LATAM Airlines—South America’s largest airline uses G Suite to connect teams, and GCP for data analytics and creating 3D digital elevation models.
LG CNS—LG is looking to Google Cloud AI, Cloud IoT Edge and Edge TPU to build its Intelligent Vision inspection tool for better quality and efficiency in some of its factories.
HSBC—One of the world’s leading banking institutions shares how they’re using data analytics on Google Cloud to extract meaningful insights from its 100PB of data and billions of transactions.
The New York Times—The newest way the New York Times is using Google Cloud is to scan, encode, and preserve its entire historical photo archive and evolve the way the newsroom tells stories by putting new tools for visual storytelling in the hands of journalists.
Nielsen—To support its nearly 45,000 employees in 100 countries with real-time collaboration and cost-effective video conferencing, Nielsen turned to G Suite.
Ocado—This online-only supermarket uses Google Cloud’s AI capabilities to power its machine learning model for responding to customer requests and detecting fraud much faster.
PayPal—PayPal discusses the hows and whys of their journey to the public cloud.
Scotiabank—This Canadian banking institution shares its views on modernizing and using the cloud to solve inherent problems inside an organization.
Sky—The UK media company uses Google Cloud to identify and disconnect pirate streaming sites during live sporting events.
Target—Moving to Google Cloud has helped Target address challenges like scaling up for Cyber Monday without disruptions, and building new, cutting-edge experiences for their guests.
20th Century Fox—The renowned movie studio shares how it’s using BigQuery ML to understand audience preferences.
Twitter—Twitter moved large-scale Hadoop clusters to GCP for ad hoc analysis and cold storage, with a total of about 300 PB of data migrated.
Veolia—This environmental solution provider moved its 250 systems to G Suite for their anytime, anywhere, any-device cloud project.
Weight Watchers—How Weight Watchers evolved its business, including creating mobile app and an online community to support its customers’ lifestyles.
Partners
2017 Partner Awards—Congratulations to the winners! These awards recognize partners who dedicated themselves to creating industry-leading solutions and strong customer experiences with Google Cloud.
SAP and Deloitte collaboration—Customers can run SAP apps on GCP with Deloitte’s comprehensive tools.
Updates to our Cisco partnership—Includes integrations between our new Call Center AI solution and Cisco Customer Journey solutions, integrations with Webex and G Suite, and a new developer challenge for hybrid solutions.
Digital Asset and BlockApps—These launch partners are helping users try Distributed Ledger Technology (DLT) frameworks on GCP, with open-source integrations coming later this year.
Intel and Appsbroker—We’ve created a cloud center of excellence to make high-performance cloud migration a lot easier.
NetApp—New capabilities help customers access shared file systems that apps need to move to cloud, plus Cloud Volumes are now available to more GCP customers.
VMware vRealize Orchestrator—A new plug-in makes it easy to use GCP alongside on-prem VMware deployments for efficient resource provisioning.
New partner specializations—We’ve recently welcomed 19 partners in five new specialization areas (bringing the total areas to nine) so customers can get even more industry-specific help moving to cloud.
SaaS-specific initiative—A new set of programs to help our partners bring SaaS applications to their customers.
Accenture Google Cloud Business Group, or AGBG—This newly formed group brings together experts who’ll work with enterprise clients to build tailored cloud solutions.
Partnership with NIH—We’re joining with the National Institutes of Health (NIH) to make more research datasets available, integrate researcher authentication and authorization mechanisms with Google Cloud credentials, and support industry standards for data access, discovery, and cloud computation.
Partnership with Iron Mountain—This new partnership helps enterprises extract hard-to-find information from inside their stored documents.
Chrome, Devices and Mobility
Cloud-based browser management—From a single view, admins can manage Chrome Browser running on Windows, Mac, Chrome OS and Linux.
Password Alert Policy—Admins can set rules to prevent corporate password use on sites outside of the company’s control.
Managed Google Play (out of beta)—Admins can curate applications by user groups as well as customize a broad range of policies and functions like application blacklisting and remote uninstall.
Google Cloud Platform | AI and machine learning
Cloud AutoML Vision, AutoML Natural Language, and AutoML Translation (all three in beta)—Powerful ML models that can be extended to suit specific needs, without requiring any specialized knowledge in machine learning or coding.
Cloud Vision API (GA)—Cloud Vision API now recognizes handwriting, supports additional file types (PDF and TIFF), and can identify where an object is located within an image.
Cloud Text-to-Speech (beta)—Improvements to Cloud Text-to-Speech offer multilingual access to voices generated by DeepMind WaveNet technology and the ability to optimize for the type of speaker you plan to use.
Cloud Speech-to-Text—Updates to this API help you identify what language is being spoken, plus provide word-level confidence scores and multi-channel (multi-participant) recognition.
Training and online prediction through scikit-learn and XGBoost in Cloud ML Engine (GA) —While Cloud ML Engine has long supported TensorFlow, we’re releasing XGBoost and scikit-learn as alternative libraries for training and classification.
Kubeflow v0.2—Building on the previous version, Kubeflow v0.2 makes it easier for you to use machine learning software stacks on Kubernetes. Kubeflow v0.2 has an improved user interface and several enhancements to monitoring and reporting.
Cloud TPU v3 (alpha)—Announced at this year’s I/O, our third-generation TPUs are now available for Google Cloud customers to accelerate training and inference workloads.
Cloud TPU Pod (alpha)—Second-generation Cloud TPUs are now available to customers in scalable clusters. Support for Cloud TPUs in Kubernetes Engine is also available in beta.
Phone Gateway in Dialogflow Enterprise Edition (beta)—Now you can assign a working phone number to a virtual agent—all without infrastructure. Speech recognition, speech synthesis, natural language understanding and orchestration are all managed for you.
Knowledge Connectors in Dialogflow Enterprise Edition (beta)—These connectors understand unstructured documents like FAQs or knowledge base articles and complement your pre-built intents with automated responses sourced from internal document collections.
Automatic Spelling Correction in Dialogflow Enterprise Edition (beta)—Natural language understanding can sometimes be challenged by spelling and grammar errors in a text-based conversation. Dialogflow can now automatically correct spelling mistakes using technology similar to what’s used in Google Search and other products.
Sentiment Analysis in Dialogflow Enterprise Edition (beta)—Relies on the Cloud Natural Language API to optionally inspect a request and score a user's attitude as positive, negative or neutral.
Text-to-Speech in Dialogflow Enterprise Edition (beta)—We’re adding native audio response to Dialogflow to complement existing Speech-to-Text capability.
Contact Center AI (alpha)—A new solution which includes new Dialogflow features alongside other tools to perform analytics and assist live agents.
Agent Assist in Contact Center AI (alpha)—Supports a live agent during a conversation and provides the agent with relevant information, like suggested articles, in real-time.
Conversational Topic Modeler in Contact Center AI (alpha)—Uses Google AI to analyze historical audio and chat logs to uncover insights about topics and trends in customer interactions.
Google Cloud Platform | Infrastructure services
Managed Istio (alpha)—A fully-managed service on GCP for Istio, an open-source project that creates a service mesh to manage and control microservices.
Istio 1.0—Speaking of open-source Istio, the project is imminently moving up to version 1.0.
Apigee API Management for Istio (GA)—Soon you can use your existing Apigee Edge API management platform to wrangle microservices running on the Istio service mesh.
Stackdriver Service Monitoring (early access)—A new view for our Stackdriver monitoring suite that shows operators how their end users are experiencing their systems. This way, they can manage against SRE-inspired SLOs.
GKE On-Prem with multi-cluster management (coming soon to alpha)—A Google-configured version of Kubernetes that includes multi-cluster management and can be deployed on-premise or in other clouds, laying the foundation for true hybrid computing.
GKE Policy Management (coming soon to alpha)—Lets you take control of your Kubernetes environment by applying centralized policies across all enrolled clusters.
Resource-based pricing for Compute Engine (rolling out this fall)—A new way we’re calculating sustained use discounts on Compute Engine machines, aggregating all your vCPUs and memory resources to maximize your savings.
Google Cloud Platform | Application development
GKE serverless add-on (coming soon to alpha)—Runs serverless workloads that scale up and down automatically, or respond to events, on top of Kubernetes Engine.
Knative—The same technologies included in the GKE serverless add-on are now available in this open-source project.
Cloud Build (GA)—Our fully managed continuous integration and continuous delivery (CI/CD) platform lets you build container and non-container artifacts and integrates with a wide variety of tools from across the developer ecosystem.
GitHub partnership—GitHub is a popular source code repository, and now you can use it with Cloud Build.
New App Engine runtimes—We’re adding support for the popular Python 3.7 and PHP 7.2 runtimes to App Engine standard environment.
Cloud Functions (GA)—Our event-driven serverless compute service is now generally available, and includes support for additional languages, plus performance, networking and security features.
Serverless containers on Cloud Functions (early preview)—Packages a function within a container, to better support custom runtimes, binaries and frameworks.
Google Cloud Platform | Data analytics
BigQuery ML (beta)—A new capability that allows data analysts and data scientists to easily build machine learning models directly from BigQuery with simple SQL commands, making machine learning more accessible to all.
BigQuery Clustering (beta)—Creates clustered tables in BigQuery as an added layer of data optimization to accelerate query performance.
BigQuery GIS (public alpha)—New functions and data types in BigQuery that follow the SQL/MM Spatial standard. Handy for PostGIS users and anyone already doing geospatial analysis in SQL.
Sheets Data Connector for BigQuery (beta)—A new way to directly access and refresh data in BigQuery from Google Sheets.
Data Studio Explorer (beta)—Deeper integration between BigQuery and Google Data Studio to help users visualize query results quickly.
Cloud Composer (GA)—Based on the open source Apache Airflow project, Cloud Composer distributes workloads across multiple clouds.
Customer Managed Encryption Keys for Dataproc—Customer-managed encryption keys that let customers create, use and revoke key encryption for BigQuery, Compute Engine and Cloud Storage. Generally available for BigQuery; beta for Compute Engine and Cloud Storage.
Streaming analytics updates, including Python Streaming and Dataflow Streaming Engine (both in beta)—Provides streaming customers more responsive autoscaling on fewer resources, by separating compute and state storage.
Dataproc Autoscaling and Dataproc Custom Packages (alpha)—Gives users Hadoop and Spark clusters that scale automatically based on the resource requirements of submitted jobs, delivering a serverless experience.
Google Cloud Platform | Databases
Oracle workloads on GCP—We’re partnering with managed service providers (MSPs) so you can run Oracle workloads on GCP using dedicated hardware.
Compute Engine VMs powered by Intel Optane DC Persistent Memory—Lets you run SAP HANA workloads for more capacity at lower cost.
Cloud Firestore (beta)—Helps you store, sync and query data for cloud-native apps. Support for Datastore Mode is also coming soon.
Updates to Cloud Bigtable—Regional replication across zones and Key Visualizer, in beta, to help debug performance issues.
Updates to Cloud Spanner—Lets users import and export data using Cloud Dataflow. A preview of Cloud Spanner’s data manipulation language (DML) is now available.
Resource-based pricing model for Compute Engine—A new billing model gives customers more savings and a simpler bill.
Google Cloud Platform | IoT
Edge TPU (early access)—Google’s purpose-built ASIC chip that’s designed to run TensorFlow Lite ML so you can accelerate ML training in the cloud and utilize fast ML inference at the edge.
Cloud IoT Edge (alpha)—Extends data processing and machine learning capabilities to gateways, cameras and end devices, helping make IoT devices and deployments smart, secure and reliable.
Google Cloud Platform | Security
Context-aware access—Capabilities to help organizations define and enforce granular access to GCP APIs, resources, G Suite, and third-party SaaS apps based on a user’s identity, location and the context of their request.
Titan Security Key—A FIDO security key that includes firmware developed by Google to verify its integrity.
Shielded VMs (beta)—A new way to leverage advanced platform security capabilities to help ensure your VMs haven’t been tampered with or compromised.
Binary Authorization (alpha)—Lets you enforce signature validation when deploying container images.
Container Registry Vulnerability Scanning (alpha)—Automatically performs vulnerability scanning for Ubuntu, Debian and Alpine images to help ensure they are safe to deploy and don’t contain vulnerable packages.
Geo-based access control in Cloud Armor (beta)—Lets you control access to your services based on the geographic location of the client trying to connect to your application.
Cloud HSM (alpha)—A fully managed cloud-hosted hardware security module (HSM) service that allows you to host encryption keys and perform cryptographic operations in FIPS 140-2 Level 3 certified HSMs.
Access Transparency (coming soon to GA)—Provides an audit trail of actions taken by Google Support and Engineering in the rare instances that they interact with your data and system configurations on Google Cloud.
G Suite | Enterprise collaboration and productivity
New investigation tool in the Security Center (Early Adopter Program)—A new tool in the security center for G Suite that helps admins identify which users are potentially infected, see if anything’s been shared externally and remove access to Drive files or delete malicious emails.
Data Regions for G Suite (available now for G Suite Business and Enterprise customers)—Lets you choose where to store primary data for select G Suite apps—globally, distributed, U.S. or Europe.
Smart Reply in Hangouts Chat—Coming soon to G Suite, Smart Reply uses artificial intelligence to recognize which emails need responses and proposes reply options.
Smart Compose in Gmail—Coming soon to G Suite, Smart Compose intelligently autocompletes emails for you by filling in greetings, common phrases and more.
Grammar Suggestions in Google Docs (Early Adopter Program)—Uses a unique machine translation-based approach to recognize grammatical errors (simple and complex) and suggest corrections.
Voice Commands for Hangouts Meet hardware (coming to select Hangouts Meet hardware customers later this year)—Brings some of the same magic of the Google Assistant to the conference room so that teams can connect to video meetings quickly.
The new Gmail (GA)—Features like redesigned security warnings, snooze and offline access are now generally available to G Suite users.
New functionality in Cloud Search—Helps organizations intelligently and securely index third-party data beyond G Suite (whether the data is stored in the cloud or on-prem).
Google Voice to G Suite (Early Adopter Program)—An enterprise version of Google Voice that lets admins manage users, provision and port phone numbers, access detailed reports and more.
Standalone offering of Drive Enterprise (GA)—New offering with usage-based pricing to help companies easily transition data from legacy enterprise content management (ECM) systems.
G Suite Enterprise for Education—Expanding to 16 new countries.
Jamboard Mobile App—Added features for Jamboard mobile devices, including new drawing tools and a new way to claim jams using near-field communication (NFC).
Salesforce Add-on in Google Sheets—A new add-on that lets you import data and reports from Salesforce into Sheets and then push updates made in Sheets back to Salesforce.
Social Impact
Data Solutions for Change—A program that empowers nonprofits with advanced data analytics to drive social and environmental impact. Benefits include role-based support and Qwiklabs.
Visualize 2030—In collaboration with the World Bank, the United Nations Foundation, and the Global Partnership for Sustainable Development Data, we’re hosting a data storytelling contest for college or graduate students.
Harambee Youth Employment Accelerator—We’re helping Harambee connect more unemployed youth with entry-level positions in Johannesburg by analyzing large datasets with BigQuery and machine learning on Cloud Dataflow.
Foundation for Precision Medicine—We’re aiding the Foundation for Precision Medicine to find a cure for Alzheimer’s disease by scaling their patient database to millions of anonymized electronic medical record (EMR) data points, creating custom modeling, and helping them visualize data.
Whew! That was 104. Thanks to all our customers, partners, and Googlers for making this our best week of the year.
But wait, there’s more! Here’s the 105th announcement: Next 2019 will be April 9-11 at the newly renovated Moscone in San Francisco. Please save the date!
Source : The Official Google Blog via Source information
0 notes
Text
Accelerating the journey to the cloud for SAP customers—access transparency preview and new certifications
From the moment we announced a partnership with SAP at Google Cloud Next in March, we’ve been busy readying SAP systems to run effectively on Google Cloud Platform (GCP). Our momentum with SAP offers solutions for all types of business, from SMBs to the largest enterprises around the world, including developments with data access transparency, a sandbox environment, application migration and integrations for business systems. We’re also continuing to build on our progress with larger HANA certifications.
This week, we’ll be on-site talking about the latest at SAP TechEd in Barcelona. Here’s an update on what we're launching.
Access Transparency and the data custodian model
Managing and mitigating risk is a priority for any organization adopting the public cloud. As part of our partnership, SAP and Google have proposed a data custodian model that will allow enterprises to continuously monitor risk and help with their data protection and access control policies. Today, we're announcing a preview of Access Transparency, a new GCP security feature that helps enable this model.
Access Transparency provides visibility into operational access by Google employees to cloud systems that store, secure or process customer data. Cloud providers may require operational access to address a customer support request, or, more rarely, to review whether a service can meet its availability and performance objectives. Access Transparency log entries include justification for access, the specific resource that was accessed, the time of access, and the corporate location of the accessor. Access Transparency enables security and compliance teams to gain meaningful oversight of their cloud provider.
We're opening up an early access preview of Access Transparency to customers. The early access preview will provide visibility into operational access for a select set of GCP services—Google Cloud Storage (GCS), Identity and Access Management (IAM), Key Management Service (KMS) and Google App Engine (GAE). We intend to progressively roll out this capability to other GCP services that store, secure or process customer data.
To express interest in our Access Transparency early access preview, please complete the online request form.
SAP platform certifications
SAP offers an extensive ecosystem of products to address the needs of SMBs to the largest enterprises. The following systems are now all certified by SAP to run on GCP:
SAP HANA: SAP HANA is now certified to run in Compute Engine instances (VMs) of up to 1.4TBs of memory. For customers running analytics applications like SAP BW or SAP Customer Activity Repository (SAP CAR), we can now support scale-out configurations with up to 16 instances, for 22TB of total memory. Additionally, we have already announced our intention to quickly enable VMs with 4TB of memory in the short term.
The SAP Data Migration Option (DMO) is now certified for migrating on-premise SAP HANA and any DB-based SAP applications to SAP HANA on GCP.
SAP Hybris e-commerce and marketing solutions are now officially supported on GCP, enabling joint customers like Smyths Toys to further integrate its business systems and drive efficiency and value.
SAP BusinessObjects Business Intelligence (BI) platform is certified to run on both Windows and Linux environments on GCP.
SAP Business One, SAP’s small business software for ERP, is now certified to run on GCP. Customers like Sale Stock in Indonesia are leveraging GCP to run their mission critical Business One solutions.
For customers who want bring up non-production SAP applications on GCP, the SAP Cloud Appliance Library now supports GCP. With the click of a button, you can spin up a sandbox environment with SAP applications like S/4 HANA on GCP and incubate exploratory projects.
SAP Vora - Version 1.4 of SAP’s in-memory distributed computing system for big data analytics is supported on GCP and what’s more, version 2.2 leverages Kubernetes and will have support for Google Container Engine and Google’s managed Hadoop service Google Cloud DataProc in Q1 2018.
Manage, monitor and extend SAP
Running SAP on GCP is one thing. Integrating it into your larger IT environment is another. Together, Google Cloud and SAP have been working hard to certify the tools you need to make the most of your SAP environment.
Customers can now implement data tiering between SAP HANA and Google BigQuery using sample tools published by Google Cloud.
It’s now easier than ever to monitor performance from within the GCP console. A new monitoring agent is available to reliably collect and publish metrics from your SAP HANA instance to GCP Stackdriver, letting you set event notifications so you can have actionable insights around aggregated data. Get started now with this user guide.
Visit us online and at SAP TechEd Barcelona
We’re working hard to make Google Cloud the best place to run SAP applications. Visit us anytime online to learn more about the SAP Google partnership. And if you’re attending SAP TechEd in Barcelona, be sure to stop by the Google Cloud booth P13 to say hello, see some demos in action and share your thoughts on how we can help accelerate your journey to the cloud.
Accelerating the journey to the cloud for SAP customers—access transparency preview and new certifications published first on http://ift.tt/2uQVASU
0 notes